ML/DL 평가지표 정리
ML/DL 모델을 평가할 때는 문제 유형(회귀, 분류, 불균형, 추천, 랭킹)에 따라 적절한 지표를 선택해야 한다.
아래는 상황별로 가장 자주 사용하는 지표들을 정리한 문서이다.
1. 분류(Classification) 평가 지표
Accuracy(정확도)
가장 기본적인 분류 지표이지만 불균형 데이터에서는 오해를 일으킬 수 있음.
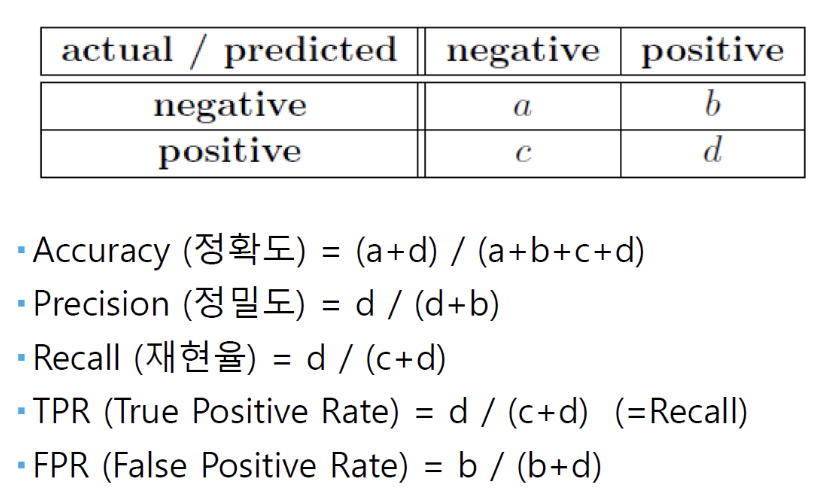
$Accuracy = \frac{TP + TN}{TP + TN + FP + FN}$
Precision(정밀도)
예측을 positive로 한 것 중 실제로 맞은 비율.
$Precision = \frac{TP}{TP + FP}$
Specificity(특이도)
예측을 negative로 한 것 중 실제로 맞은 비율.
$Specificity = \frac{TN}{FP + TN}$
Recall(재현율) = Sensitifity(민감도)
실제로 positive인 것 중 모델이 맞게 찾아낸 비율.
$Recall = \frac{TP}{TP + FN}$
F1 Score
Precision과 Recall의 조화평균.
$F1 = 2 \cdot \frac{Precision \cdot Recall}{Precision + Recall}$
1) F1-micro
- 전체 표본 기준으로 평균
→ 불균형 문제에서 큰 클래스에 민감
2) F1-macro
- 클래스별 F1의 평균
→ 불균형 문제에서 모든 클래스를 동등하게 반영
ROC-AUC
- ROC 커브 아래의 면적이다.
- 모델의 전반적 분류 성능을 확률 기반으로 평가.
- 커브 아래 면적이 1에 가까울수록 우수.
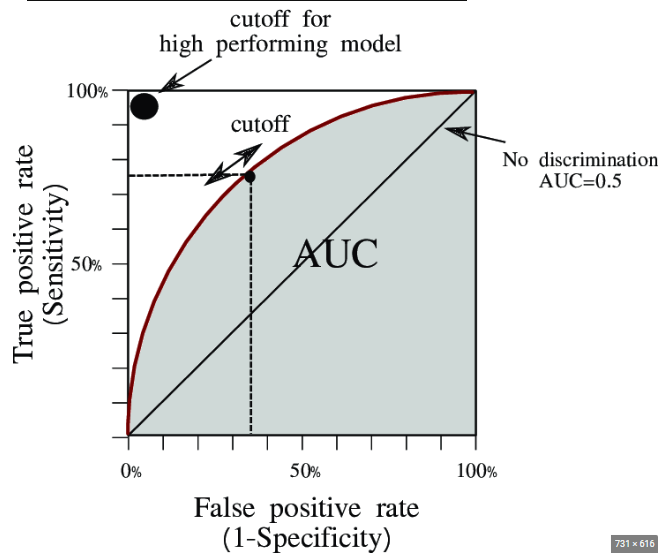
- x축 False Positive Rate(=1-특이도) : 음성인 케이스에 대해 양성로 잘못 예측한 비율. (정상환자를 암이라고 진단 함)
- y축 True Negative Rate(=특이도) : 음성인 케이스에 대해 음성으로 잘 예측한 비율 (정상환자를 정상이라고 진단)
PR-AUC (Precision–Recall AUC)
- 극단적 불균형 문제에서 ROC-AUC보다 더 유의미함.
FI (Fraud Indicator)
- 이상탐지/사기탐지에서 사용하는 지표(업계에서 커스텀적으로 정의).
2. 회귀(Regression) 평가 지표
MAE (Mean Absolute Error)
$MAE = \frac{1}{N}\sum (abs(y - \hat{y}))$
MSE (Mean Squared Error)
- 회귀 모델의 평가 지표로 많이 사용되는 평가 지표이다.
$MSE = \frac{1}{N}\sum (y - \hat{y})^2$
RMSE (RMSE (Root Mean Squared Error)
$RMSE = \sqrt{MSE}$
R² Score (결정계수)
- 독립변수가 종속변수를 얼마나 잘 설명하는 지를 나타낸다.
$R^2 = 1 - \frac{\sum (y-\hat{y})^2}{\sum (y-\bar{y})^2} = \frac{SSR}{SST} = 1 - \frac{SSE}{SST}$
3. 추천 시스템(Recommender System) 지표
추천 시스템은 모델이 “얼마나 사용자 취향을 잘 맞추는지” 평가하는 지표를 사용한다.
Hit@K
- Top-K 추천 목록에 실제 정답이 포함되었는지 여부.
- QA에서도 평가지표로 쓰인다.
- 검색엔진이 뽑은 Top-K 문서(또는 패시지) 중에 정답 패시지가 있으면 Hit.
- 핵심은 “Top-K 안에 정답이 있는가?”
$Hit@K =
\begin{cases}
1 & \text{if item in Top K}
0 & \text{otherwise}
\end{cases}$
Recall@K
사용자가 실제 좋아한 아이템 중 추천으로 얼마나 포함되었는지.
$Recall@K = \frac{Relevant \cap Recommended@K}{Relevant}$
Precision@K
추천한 K개 중에서 실제 사용자가 좋아한 비율.
$Precision@K = \frac{Relevant \cap Recommended@K}{K}$
4. LLM 답변 평가
Ground Truth 기반 LLM Judge (AI 채점관 활용)
- 질문에 대한 “기준 정답(Ground truth)” 만들기
- 사람이 직접 만들거나 약관 텍스트에서 골라내서 생성 가능
- LLM에게 “문서 기반 정확한 핵심 요약” 요청해 기준 정답 생성 가능
- LLM Judge에게 비교 평가시키기
Retrieval Ground Truth 기반 평가 (문서 출처가 맞는지 평가)
-
답변 품질을 직접 판단하는 대신, retriever가 올바른 문서를 가져왔는지 평가하는 방식
- “자녀보험 질문인데” → 자녀 약관 청크를 가져왔는가?
- “운전자보험 질문인데” → 자동차 약관 청크가 섞여 있는가?