추천 시스템 총정리 : CBF & CF & GNN
기본 용어
종류
| Explicit data | Implicit data |
|---|---|
| 명확하게 자신의 취향을 나타내는 데이터 | 취향을 추론할 수 있는 데이터 |
| 점수 / 좋아요,구독 / 구매 / 장바구니 담기 | click → 머무는 시간, 방문 횟수 / 시청 여부, 시청 시간 / 장바구니 담기 |
CF (Collaborative Filtering)
- 가장 보편적으로 많이 알려지고 사용되는 추천 알고리즘이다.
- 다른 유저의 추천 데이터들을 바탕으로 시스템을 구현한다.
-
사용자들의 데이터를 바탕으로 추천을 구축한다는 점이 포인트!
- 기본 가정
- 사용자로부터 아이템에 대한 명시적/묵시적 평가를 데이터로 구할 수 있다.
- 사용자들의 평가 데이터에서 취향이 비슷한 사람을 찾아낼 수 있고, 취향이 비슷한 사람들은 선호 패턴이 비슷하다.
-
유사도 지표
1) Correlation coefficient (상관계수)
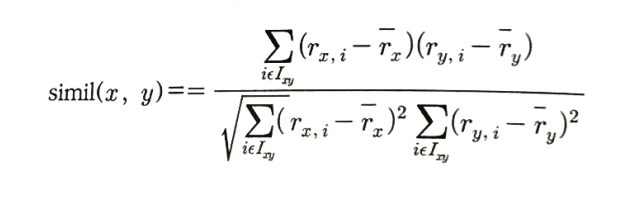
문자 의미 $x, y$ 두 사용자(user) (또는 두 아이템(item)) $r_{x,i}$ 사용자 (x)가 아이템 (i)에 준 평점 $r_{y,i}$ 사용자 (y)가 아이템 (i)에 준 평점 $\bar{r}_x$ 사용자 (x)의 평균 평점 $\bar{r}_y$ 사용자 (y)의 평균 평점 $I_{xy}$ 사용자 (x)와 (y)가 모두 평가한(공동 평가) 아이템들의 집합 2) 코사인 유사도
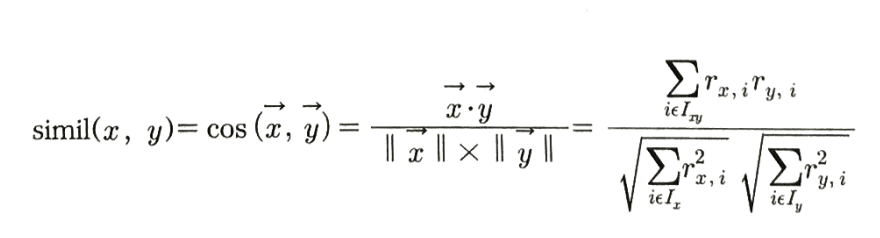
기호 의미 $\vec{x}, \vec{y}$ 사용자 (x), 사용자 (y)의 평점 벡터 $r_{x,i}, r_{y,i}$ 각 사용자가 아이템 (i)에 준 평점 $I_x$ 사용자 (x)가 평가한 아이템들의 집합 $I_y$ 사용자 (y)가 평가한 아이템들의 집합 $I_{xy}$ 두 사용자가 모두 평가한 아이템들의 집합 $\vec{x} \cdot \vec{y}$ 두 벡터의 내적 $∥\vec{x}∥$ 사용자 (x)의 평점 벡터 크기(norm) 3) Tanimoto coefficient
 - 고전적인 방법이다.
- 고전적인 방법이다. - 작동 방식
-
모든 사용자간의 평가 유사도를 계산한다. 상관계수, 코사인 등 사용
-
추천 대상과 다른 사용자들의 유사도를 추출한다.
- 추천 대상이 평가하지 않은 모든 아이템에 대해서, 추천 대상의 예상 평가 값을 구한다.
- 예상 평가값은 다른 사용자의 해당 아이템에 대한 평가와 그 사용자와의 유사도를 가중평균으로 계산한다.
- 아이템 중에서 예상 평가값이 가장 높은 N개의 아이템을 추천한다
-
사용자들의 데이터를 바탕으로 추천을 구축하는데,
하위 항목으로 아이템 기반 필터링(Item-based Filtering) 과
유저 기반 필터링(User-based Filtering) 으로 구분된다.
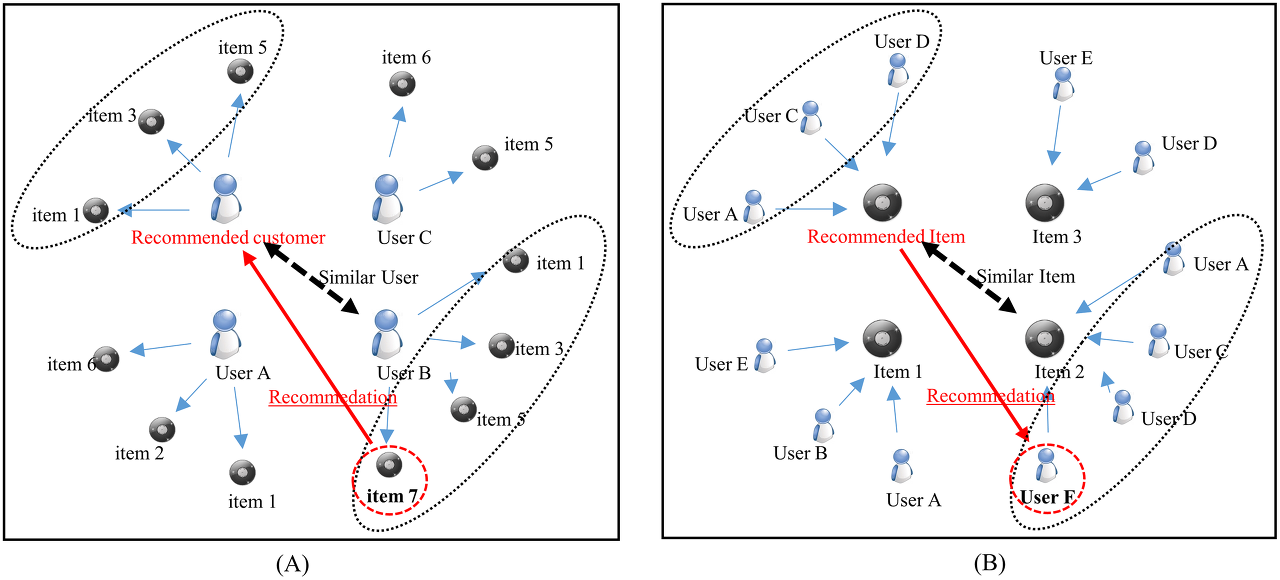 (A) User-Based
(B) Item-Based
(A) User-Based
(B) Item-Based
1. Item-based Collaborative Filtering(IBCF)
- 영화 추천 시스템을 예로 들면 유사한 두 영화에 대해 비슷한 평점을 남길 것이라는 생각에서 출발한다.
-
CBF와 동일한 과정이나 유사도를 구하는 과정에서 차이가 있다.
 =>
=> - 아이템간 유사도 사용 → 사용자가 선택한 아이템이 같으면 동일한 추천리스트
- 장점
-
Robustness가 높음 = Coverage가 높음
→ 사용자가 아이템 하나만 평가하면 추천이 가능하다. 유저가 평가를 많이 안 해도 “그나마 하나라도 평점/클릭한 아이템이 있으면” 그 순간 추천이 가능해진다.
-
- 계산 예시

2. User-based Collaborative Filtering(UBCF)
- 영화 추천 시스템을 예로 들면 유사한 유저는 같은 영화에 대해 비슷한 평점을 남길 것이라는 생각에서 출발한다.
-
사용자간 유사도 사용 → 사용자별로 개인화된 추천 리스트

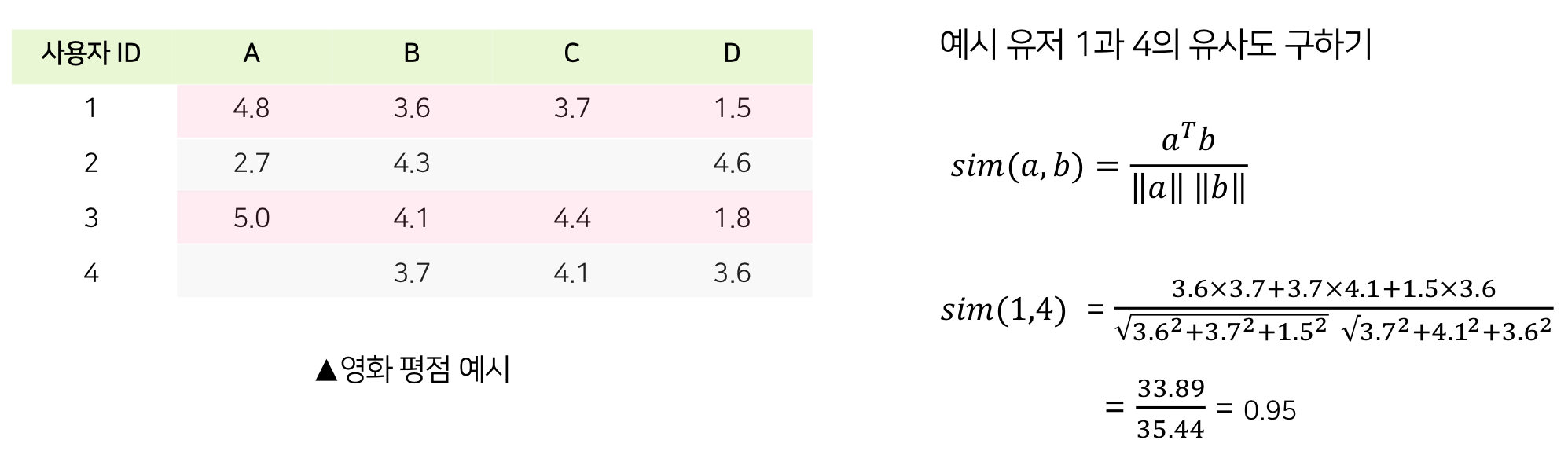
- 계산 예시
CBF (Content - Based Filtering)
- 아이템 고유 정보를 기반으로 하는 추천으로 사용자의 상호 작용 정보 없이 추천 수행이 가능하다!
- IBCF는 특정 컨텐츠에 대해서 다른 유저들이 남긴 평점을 기반으로 유사도를 계산해서 추천을 진행하지만, 내용 기반 추천은 해당 컨텐츠의 내용 자체의 유사도로 추천하는 방식이다.

- 장점
-
다른 유저들의 데이터를 필요로 하지 않는다.
=> 새로운 아이템이 추가 됐을 때 Cold Start Problem에서 자유로워진다.
- 개인의 취향을 고려한 추천이 가능하다.
-
새로운 아이템이나 대중적이지 않은 아이템도 추천할 수 있다.
=> 아무도 평가하지 않은 새로운 아이템과 인기 없는 아이템도 해당 아이템들의 Feature들만 뽑아낼 수 있다면, CF 구현시 발생하는 No first-rater Problem에서 자유로워진다.
- 사용자에게 추천하는 이유에 대해 설명할 수 있다.
-
- 단점
- 주변 유저 평가는 영향을 받지 않지만, 아예 처음 유입된 유저는 그에 대한 데이터가 존재하지 않아서 추천할 수 없다.
- 작동 방식
- 아이템 간의 유사도를 계산한다
- 추천 대상이 되는 사용자가 선호하는 아이템을 선정
- 2번 단계에서 선정된 아이템과 가장 유사도가 높은 N개의 아이템을 찾는다.
- 찾은 N개의 아이템을 사용자에게 추천한다.
-
계산 예시
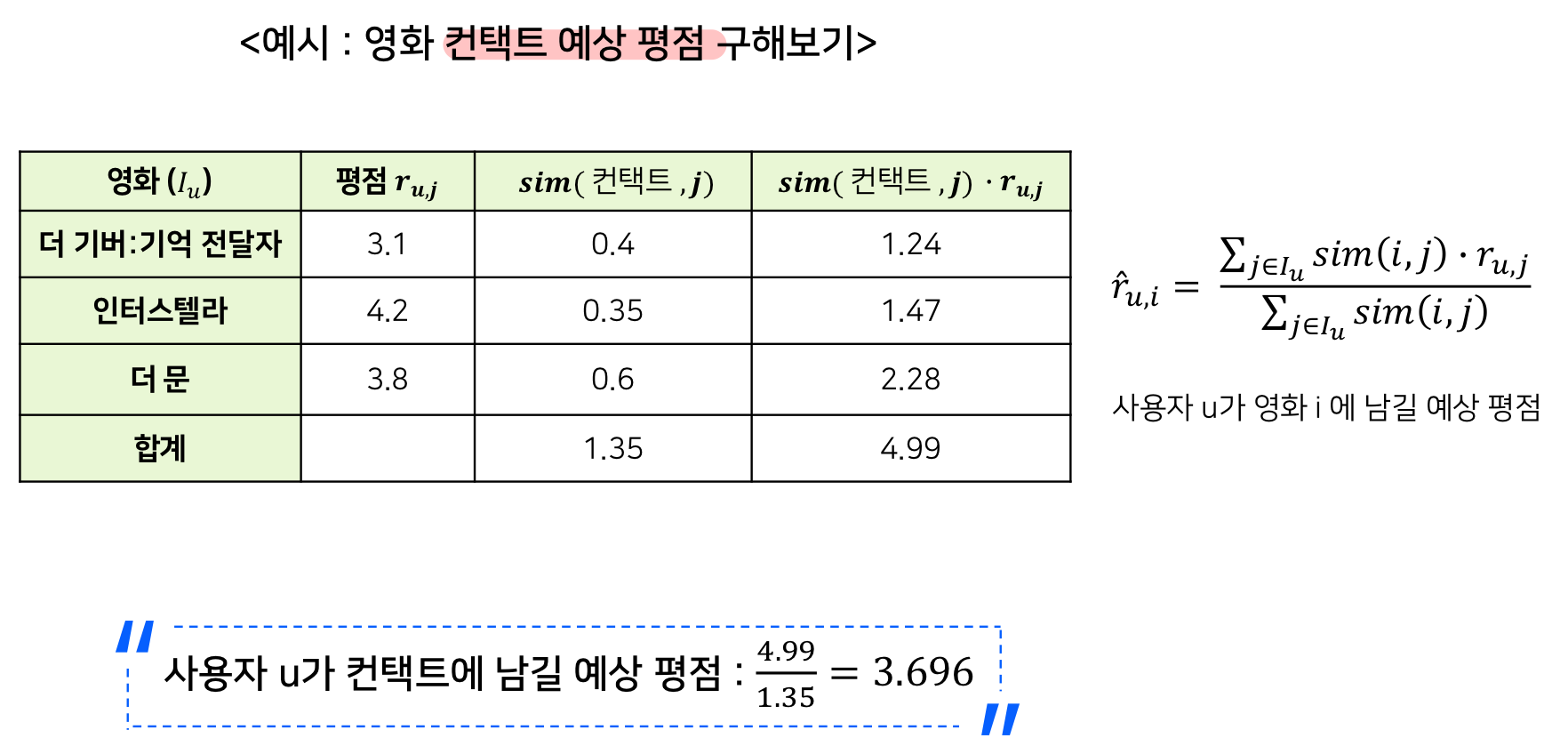
이때, 영화끼리의 유사도는 어떻게 구하는가?
아이템끼리의 컨텐츠 유사도 $(sim(i,j))$ - (1) 고전적인 방법
두 아이템간 유사도를 어떻게 정량화 할 것인가?
CBF에서는 유사도를 정량화 하기 위해서 컨텐츠 자체가 가진 특성을 이용한다.
우선, 고전적인 방식부터 알아보자.
-
집합 유사도
 => 이렇게만 계산하면 복잡한 계산은 하기 힘들어지기 때문에 유사도를 벡터 공간으로 확대한다.
=> 이렇게만 계산하면 복잡한 계산은 하기 힘들어지기 때문에 유사도를 벡터 공간으로 확대한다.TF-IDF나 BoW로 아이템을 고차원 벡터로 만들고,
Cosine similarity(또는 유클리드 거리)로 벡터 간 유사도를 측정할 수 있다.
(코사인 유사도는 위에 이미 한번 설명했으므로 생략)
- Bag-of-Words(BoW)
- 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
- ex
- 영화 A: “robot saves world”
- 영화 B: “girl saves world”
- 영화 C: “robot fights alien”
BoW는 다음처럼 단어가 등장했는지 여부 또는 등장 횟수로 벡터를 만든다.
단어 A B C robot 1 0 1 saves 1 1 0 world 1 1 0 girl 0 1 0 fights 0 0 1 alien 0 0 1 이제 영화 하나가 6차원 벡터로 표현되는 것!
- TF-IDF
- 문서 집합에서 한 단어가 얼마나 중요한지를 수치적으로 나타낸 가중치이다.
- 특정 문서에서 중요한 단어만 강조하는 BoW의 개선버전이다.
- ‘을’, ‘를’, ‘이’, ‘가’와 같은 조사들은 우리가 사용하는 문서들에 많은 부분을 차지하지만 문서의 유의미한 의미는 없다.
- 이러한 단점을 보완하기 위해 제안된 기법이 ‘TF-IDF’이다.
- 용어
- TF(Term Frequency) : 어떤 단어가 특정 문서에 얼마나 많이 쓰였는지의 빈도
- DF(Document Frequency) : 특정 단어가 나타난 문서의 수
- IDF(Inverse Document Frequency) : 전체 문서 수 N을 해당 단어의 DF로 나눈 뒤 로그를 취한 값.즉 해당 단어가 얼마나 얼마나 “희귀하게” 쓰였는지를 나타내는 지표

아이템끼리의 컨텐츠 유사도 $(sim(i,j))$ - (2) 최신 방법
현대 CBF는 컨텐츠 내용을 사전 학습 모델로 의미 기반 벡터 임베딩하고, 그 벡터 사이의 코사인 유사도 또는 내적을 사용한다.
- Sentence Embedding
- “문장 의미”를 이해함 → TF-IDF보다 훨씬 고성능이다.
- TF-IDF 시대에서는 예를 들어 영화 “아이언맨”과 “배트맨”이 로봇/과학, 어둠/부자/복수 등 단어 분포 차이 때문에 유사하지 않다고 나올 수 있었다.
- 임베딩 기반에서는 “슈퍼히어로 영화”라는 의미가 반영되어 유사도 ↑
- 모델 예시
- Sentence-BERT (SBERT)
- Sentence-T5
- MPNet embeddings
- E5-large / bge-large 같은 최신 임베딩 모델
- “문장 의미”를 이해함 → TF-IDF보다 훨씬 고성능이다.
- 멀티모달
- 이미지 ⟷ 텍스트의 의미적 유사도 계산
- 패션 추천, 인테리어 추천, 음식 추천 등에 많이 사용
딥러닝 기술의 발전으로 추천시스템에도 AI 기술을 적극적으로 활용하고 있다.
그 중에 그래프 기반의 추천시스템을 봐보자.
Graph Based Recommender System
- 접근 방식
- 모든 사용자와 항목에 대해 고품질 임베딩을 생성한다.
- 모든 사용자에 대해 임베딩을 사용하여 항목 선호도를 예측합니다.