Feature Engineering 총정리
머신러닝 프로젝트에서 모델 선택은 생각보다 중요도가 낮다.
정말 중요한 것은 데이터 전처리 + 피처 엔지니어링을 얼마나 체계적으로 했느냐이다.
복습용으로 EDA부터 데이터 전처리, feauture engineering, 변수선택 등등 프로세스 총정리 복습 한번 해야겠다.
레지고.
머신러닝 프로세스
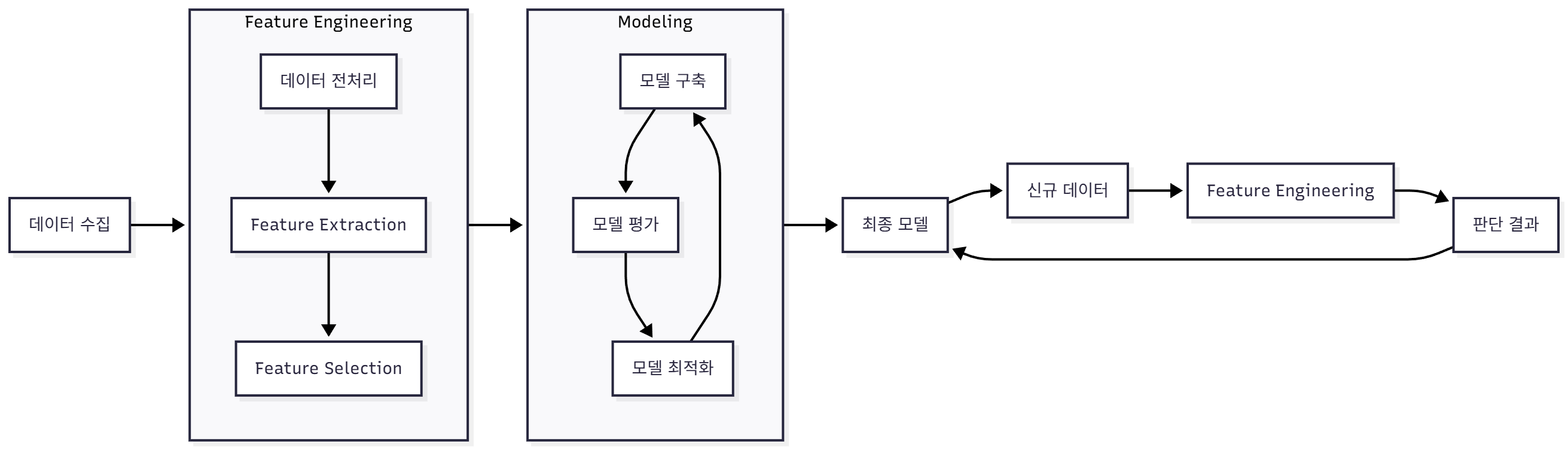
우선 해당 포스팅에서 캐글에 있는 Healthcare Risk Factors 데이터를 이용하겠다.
import kagglehub
# Download latest version
path = kagglehub.dataset_download("abdallaahmed77/healthcare-risk-factors-dataset")
print("Path to dataset files:", path)
Data info
Features
Age: 환자의 나이(연령, years)Gender: 성별 (Male, Female)Medical Condition: 건강 상태 (Diabetes, Hypertension, Asthma, Obesity, Healthy 등)Glucose: 혈당 수치Blood Pressure: 혈압 수치BMI: 체질량지수 (Body Mass Index)Oxygen Saturation: 혈중 산소포화도LengthOfStay: 입원 기간(일)Cholesterol: 콜레스테롤 수치Triglycerides: 중성지방(Triglyceride) 수치HbA1c: 당화혈색소(Hemoglobin A1c)Smoking: 흡연 여부 (0 = 비흡연, 1 = 흡연)Alcohol: 음주 여부 (0 = No, 1 = Yes)Physical Activity: 신체활동 시간(시간/주)Diet Score: 식단 품질 점수(수치형)Family History: 가족력 여부 (0 = No, 1 = Yes)Stress Level: 스트레스 수준(수치형)Sleep Hours: 하루 평균 수면 시간random_notes: 랜덤 텍스트(lorem, ipsum 등)noise_col: 의미 없는 노이즈 데이터
1. EDA (Exploratory Data Analysis)
데이터를 먼저 살펴보자.
필요한 라이브러리들을 import한ㄴ다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder, OneHotEncoder
from sklearn.impute import SimpleImputer
# plot들을 노트북 내부에서 보여주게 함
%matplotlib inline
먼저 df.info()로 칼럼들을 한눈에 봐보자.
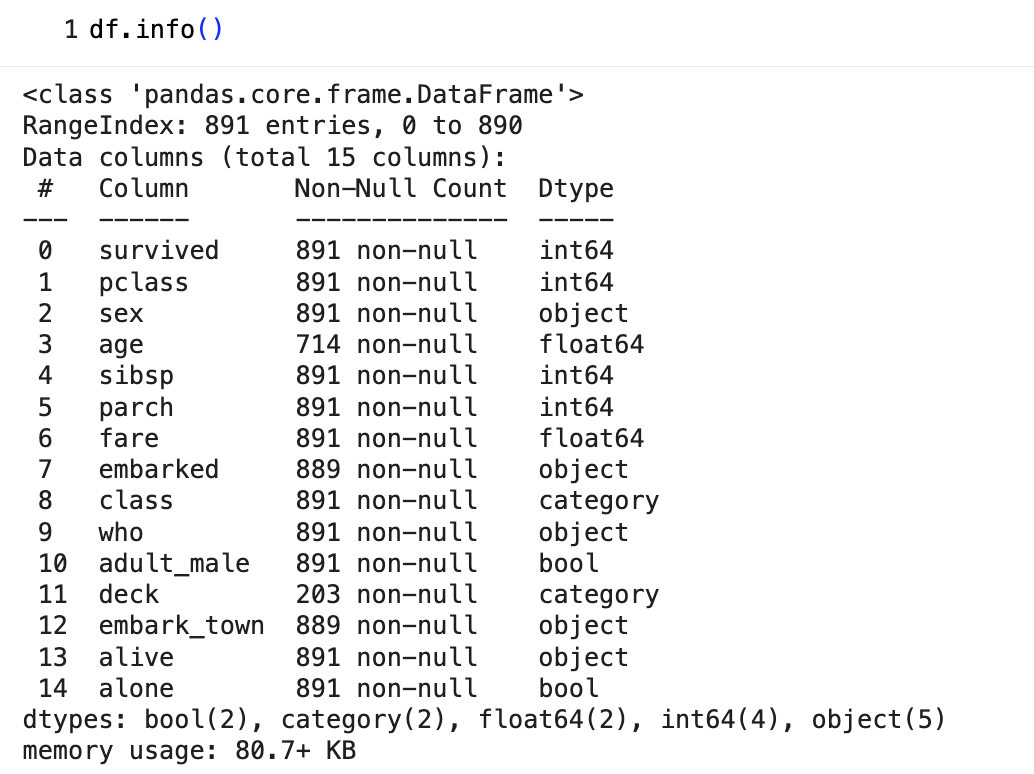
데이터 포인트가 총 30000개임을 알 수가 있고, 30000 미만인 칼럼들은 결측치가 존재함을 확인할 수 있다.
결측치가 정확히 몇개정도 되는지 확인해보자. df.isnull().sum()함수를 사용하면 각 칼럼마다 결측치 수를 알 수 있다.

기초통계량은 df.describe()로 확인한다.
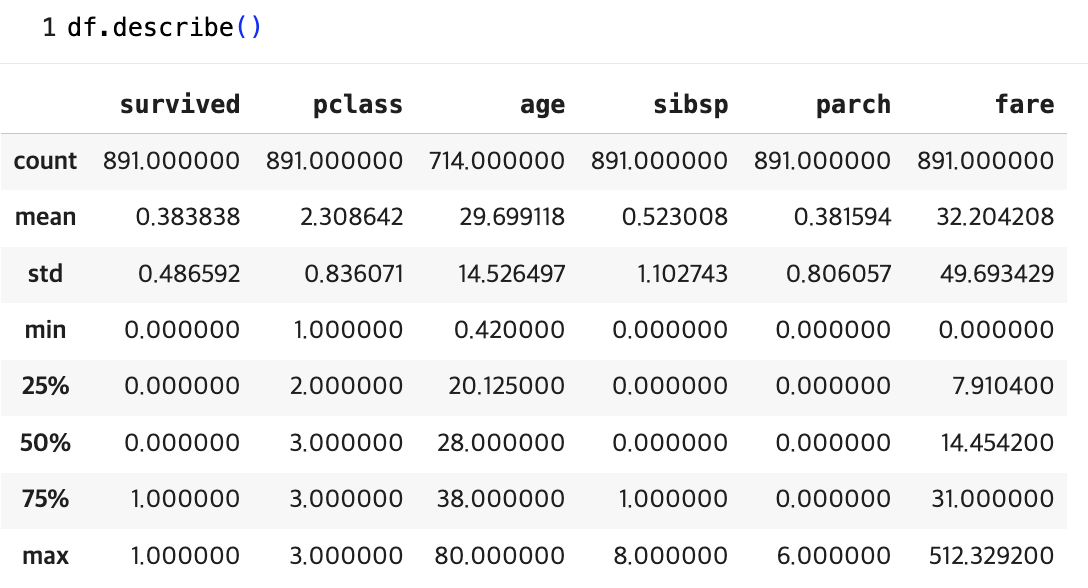
나이대 분포가 매우 다양함을 확인할 수 있다.
2. 데이터 정제 (Data Cleaning)
데이터 정제부터 해보자.
결측치 처리 (Missing Values)
결측치는 왜 비어있는지에 따라 성격이 다르다.
- MCAR (Missing Completely At Random)
- 완전히 랜덤하게 빠진 경우
- 예: 설문지 제출 중 실수로 한 칸 빔
- 데이터 자체에는 패턴이 없으므로, 단순 제거/대체가 크게 편향을 만들지 않을 수 있다.
- 완전히 랜덤하게 빠진 경우
- MAR (Missing At Random)
- 어떤 다른 변수에 의존해서 빠진 경우
- 예: 나이가 많을수록 소득을 안 적는 비율이 높음
- 다른 변수(나이 등)를 이용해 결측치를 대체하는 것이 적절하다.
- 어떤 다른 변수에 의존해서 빠진 경우
- MNAR (Missing Not At Random)
- 결측 자체가 그 값의 크기와 관련 있을 때
- 예: 소득이 매우 높거나 낮을수록 더 숨김 → 소득 자체가 결측의 원인
- 단순 average imputation 등은 위험하다. 별도 모델링, 도메인 지식 필요.
- 결측 자체가 그 값의 크기와 관련 있을 때
보통 “왜 빠졌는지”를 전부 알 수 없으므로, EDA로 패턴을 보고 ‘의심’하면서 전략을 세워볼 수 있다.
결측치 처리 전략
- 행/열 삭제
- 열 : 결측 비율이 너무 높은 컬럼 (예: 70% 이상)의 경우는 아예 칼럼을 제거하는 것이 나을 수 있다.
- 행 : 관측치가 충분하고, 결측치를 가진 행이 별로 없다면 제거하는 것이 나을 수 있다.
- 단순 대체
- 수치형 : 평균, 중앙값, 최빈값
- 평균
- 평균은 정규분포에 가까운 데이터, 즉 분포가 대칭적인 경우에 좋다.
- 극단적인 이상치가 거의 없을 때, 혹은 한 쪽으로 치우친 값이나 이상치가 존재하는 경우는 평균이 적절하지 않을 수 있다.(평균은 이상치 한 개로도 전체를 크게 흔들기 때문)
- 중앙값
- 중앙값은 이상치(outlier) 영향이 가장 적은 대체 방식이다.
- 데이터가 치우쳐(skewed) 있을 때, 분포가 비정규, 극단값·이상치가 많은 변수일 때 사용하기 좋다.
- 최빈값
- 최빈값은 수치형이지만 사실상 범주형처럼 취급될 때 적합하다.
- 해당 수치값이 이산적(discrete) 이고 카테고리적 특성이 있을 때 사용할 수 있다.
- 평균
- 범주형 : 최빈값, “Unknown” 카테고리
- 수치형 : 평균, 중앙값, 최빈값
- 모델 기반 대체
- 결측이 많은데 중요한 변수일 때, 다른 변수들을 사용해 “예측”해서 채우는 방법을 쓸 수 있다.
- 결측 여부 자체를 피처로 쓰기
- “결측이다 = 어떤 패턴을 의미한다”면, 결측 여부 자체를 피처로 살려볼 수도 있다.
이상치 처리 (Outlier Handling)
이상치는 항상 제거 대상은 아니다.
“도메인 상 말이 안 되는 값” vs “극단값이지만 진짜일 수 있는 값”을 구분해야 한다.
이상치 탐색 방법
- 기본 통계값 확인
- 박스플롯
- IQR 기준으로 하위 25%, 상위 75% 및 이상치 확인
- IQR = Q3 - Q1
- 히스토그램
- 분포 모양을 눈으로 파악
- Z-score 기반
- 평균에서 얼마나 떨어져 있는지 표준편차 단위로 본다.
이상치 처리 전략
- 도메인상 불가능한 값 → 수정 또는 제거
- 예: 나이 -1, 250살
-
측정/입력 오류로 의심되는 값 → 제거
- 진짜 극단값이지만 중요한 경우
- 로그 변환, 박스코스 변환으로 완화
- 로버스트 스케일러(RobustScaler) 사용
- 의도적으로 그대로 두고, 모델이 알아서 처리하도록 맡기기도 한다.
3. 데이터 변환 (Data Transformation)
데이터 변환은 “모델이 잘 학습할 수 있게 값의 스케일, 분포, 표현을 바꾸는 단계”이다.
1) 스케일링 (Scaling)
스케일이 크게 다른 피처가 섞여 있으면,
경사하강법 기반 모델 (Linear Regression, Logistic Regression, Neural Network) 의 학습이 느려지고
거리 기반 모델 (KNN, K-means, SVM with RBF) 의 결과가 왜곡된다.
정규화 (Normalization: Min-Max Scaling)
- [0, 1] 범위로 변환한다.
- 공식
- $x’ = \frac{x - x_{\min}}{x_{\max} - x_{\min}}$
- 이상치에 매우 민감하다!
표준화 (Standardization: Z-Score Scaling)
- 평균 0, 분산 1로 변환한다.
- 공식
- $x’ = \frac{x - \mu}{\sigma}$
- 대부분의 선형 모델, SVM 등에서 기본적으로 많이 사용한다.
로버스트 스케일러 (RobustScaler)
- 데이터의 중앙값을 뺀 다음, 사분위수 범위(IQR, Interquartile Range)로 나누어 데이터를 스케일링한다.
- 이 방법은 특히 이상치(outliers)에 덜 민감한 스케일링을 원할 때 유용하다.
- 공식
- $Scaled Value = \frac{(Value − Median)}{IQR}$
2) 인코딩 (Encoding)
범주형 변수를 분류기나 예측기에 넣기 전에 숫자로 인코딩을 해줘야 한다.
보통 두 가지 방법을 사용한다.
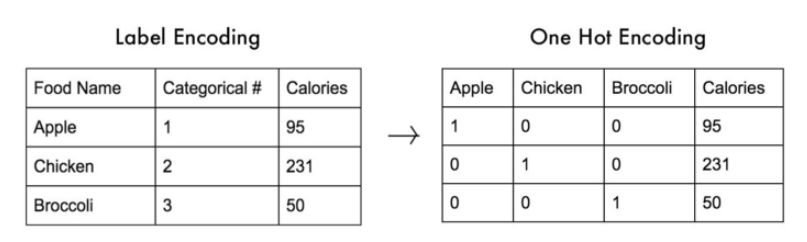
Label Encoding
- 각 카테고리를 정수로 매핑한다.
- 속성값을 그냥 정수로 바꿔주는 것이기 때문에 dataframe 자체의 크기가 커지거나 줄어들지 않는다.
- 예: {‘male’: 0, ‘female’: 1}
- 트리 기반 모델 (Decision Tree, RandomForest, XGBoost) 에서는 순서를 크게 문제 삼지 않는 경우가 많다.
- 선형 모델이나 거리 기반 모델에서 인위적인 순서 정보가 들어가 버릴 수 있어 주의한다.
One-hot Encoding
- 라벨 인코딩 방식보다 더 자주 쓰는 것이 원-핫 인코딩 방식이다.
- 고유 값에 해당하는 컬럼은 1, 나머지 컬럼에는 0을 표시하는 방식이다.
- 다시 말해, 해당 범주형 변수의 범주값 개수만큼 새로운 컬럼이 생성한다.
- 카테고리 수가 많으면 차원이 너무 커질 수 있다.
- 추가로, 단어를 표현하는 데도 원핫 인코딩 방식이 가능하다.
Ordinal Encoding (순서형)
- ‘등급’처럼 순서가 있는 범주에 사용한다.
- 범주 간에 명확한 순서가 있는 경우, 그 순서를 반영하여 정수로 변환한다.
3) 로그 변환
- 데이터 간 편차를 줄여 왜도(skewness)와 첨도(Kurtosis)를 줄일 수 있기 때문에 정규성이 높아진다.
- log 변환은 큰 수를 작게 만들 경우, 복잡한 계산을 간편하게 위할 경우 사용된다.
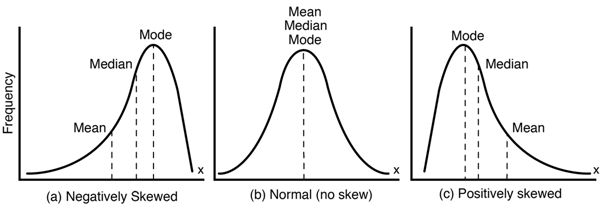
4) Box-Cox / Yeo-Johnson 변환
- 분포를 정규에 더 가깝게 만들기 위해 사용하는 변환이다.
- Box-Cox : 입력값이 양수일 때만 가능
- Yeo-Johnson : 0이나 음수도 처리 가능
4. Feature Extraction
- 피쳐들 사이에 내재한 특성이나 관계를 분석하여 이들을 잘 표현할 수 있는 새로운 선형 혹은 비선형 결합 변수를 만들어 데이터를 줄이는 방법이다.
- 고차원의 원본 피쳐 공간을 저차원의 새로운 피쳐 공간으로 투영
- ex) PCA, LDA
수치형 데이터
PCA
- 가장 널리 사용되는 차원(변수) 축소 기법 중 하나이다.(비지도학습임)
- 원 데이터의 분산(variance)을 최대한 보존하면서(최대한 기존 특징을 살리면서) 서로 직교하는 새 기저(축)를 찾아, 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법이다.
- 찾는 기저(축)이 바로 공분산 행렬의 고유벡터이다.
- 공분산 행렬은 정방행렬 & 대칭행렬이기 때문에 모든 고유벡터로 이루어진 행렬은 직교행렬이다. 즉, 모든 고유벡터들은 직교한다. 따라서 PCA에서 축들은 직교한다.
- PCA는 기존의 변수를 조합하여 서로 연관성이 없는(선형 관계가 없는) 새로운 변수, 즉 주성분(principal component, PC)들을 만들어 낸다.
-
PCA를 사용하면 다중공선성 문제, 차원의 저주 문제를 해결할 수 있고, 차원을 축소해주기때문에 사람이 쉽게 관찰하고 이해할 수 있는 2차원으로 데이터들을 보여줄 수 있다.
- 차원의 저주란?
- 차원이 증가할수록 (데이터를 표현할 수 있는 공간은 커지지만 데이터의 갯수는 그대로이기 때문에) 데이터의 밀도가 희소해지는 현상이다.
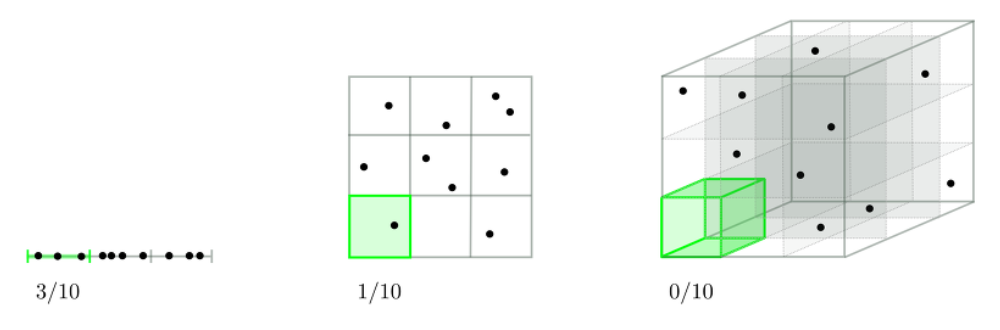
- 공간이 커진만큼 데이터 양이 따라오지 못하면, 공간별로 소수의 데이터만을 설명하여 과적합 문제가 발생할 수 있다.
- 차원이 증가할수록 (데이터를 표현할 수 있는 공간은 커지지만 데이터의 갯수는 그대로이기 때문에) 데이터의 밀도가 희소해지는 현상이다.
- 다중공선성이란?
- 변수들간의 상관관계가 높을때 문제가 발생한다. 즉, 독립변수들 간의 강한 상관관계가 나타날때 발생한다.
- 회귀분석의 가정(전제 조건)인 변수들간의 상관관계가 높으면 안된다는 가정을 위배하기 때문에 문제가 될 수 있다.
LDA
- 입력 데이터 세트를 저차원 공간으로 투영(projection)해 차원을 축소하는 기법이다.
- 데이터의 Target값 클래스끼리 최대한 분리할 수 있는 축을 찾는 지도 학습이다.
Autoencoder 기반 표현 학습
- 딥러닝을 사용해 압축된 표현(latent vector) 을 추출한다.
- 비선형 구조까지 학습할 수 있다.
시계열 데이터
시계열 데이터는 시간적인 순서(temporal order) 가 중요한 데이터이다.
Lag feature
- Lag Feature란, 과거 값을 현재 시점의 피처로 추가하는 방법이다.
- 즉, “시계열의 자기상관(autocorrelation)”을 반영하는 가장 기본적인 방법이다.
- Lag k는 다음과 같이 정의한다.
- lag 1 → 바로 전 시점 값
- lag 2 → 두 시점 전 값
이동 평균
- 이동 평균은 시계열을 부드럽게(smoothing) 만들어서 단기 노이즈 제거하고 장기 추세(trend) 파악 목적으로 사용한다.
- 종류
- 단순 이동 평균 (SMA, Simple Moving Average)
- window 안 값을 모두 동일 비중으로 평균한다.
- 지수 이동 평균 (EMA, Exponential Moving Average)
- 최신 데이터에 더 높은 가중치를 부여한다.
- 금융 시계열(주가 분석)에 많이 사용한다.
- 단순 이동 평균 (SMA, Simple Moving Average)
5. Feature Selection
- 피쳐 중 타겟에 가장 관련성이 높은 피쳐만을 선정하여 피쳐의 수를 줄이는 방법이다.
- 관련없거나 중복되는 피쳐들을 필터링하고 간결한 subset을 생성한다.
- 모델 단순화, 훈련 시간 축소, 차원의 저주 방지, 과적합(Over-fitting)을 줄여 일반화해주는 장점이 있다.
- Feature Selection은 훈련 데이터에서만 fit해야 한다.
- Train/Test leakage 방지
- 통계적으로는 저점수지만, 비즈니스적으로 중요한 피처는 남겨두는 것이 좋다.
1) Filter Methods (필터 방식)
- 모델과 독립적으로 통계적 기준만 보고 변수 선택을 한다.
-
타깃과의 상관이 높은 변수, 또는 서로 강하게 상관된(중복되는) 변수들을 보고 선택한다.
- 분류 문제에서 범주형 피처 vs 타깃 => 카이제곱 검정
- 수치형 피처 vs 범주형 타깃: ANOVA F-test
2) Wrapper Methods (래퍼 방식)
- 모델을 실제로 학습해 보면서 피처 조합을 탐색하는 방법이다.
- 장점: 모델 성능 기준이므로 실질적이다.
- 단점: 계산량이 크다.
- ex) 전체 피처로 모델을 학습 → 중요도가 낮은 피처를 제거 → 반복
3) Embedded Methods (임베디드 방식)
- 모델 학습 과정에서 가중치/중요도가 같이 학습되므로, 이를 이용해 피처를 선택한다.
L1 정규화 (-> Lasso)
- L1 penalty는 일부 가중치를 0으로 만들어 자연스럽게 변수 선택 기능을 한다.
- 학습에 영향을 미치는 cost function을 조정한다.
- 일반적인 cost function에 가중치 절대값을 더해준다.
- 편미분을 하면 w값은 상수값이 되어버리고, 그 부호에 따라 +-가 결정된다.
- 가중치가 너무 작은 경우는 상수 값에 의해서 weight가 0이 되어버린다.
- 즉, 결과적으로 몇몇 중요한 가중치들만 남게 된다.
L2 정규화 (-> Ridge)
- Cost function에 제곱한 가중치 값을 더해줌으로써 편미분을 통해 back propacation 할 때 Cost 뿐만 아니라 가중치 또한 줄어드는 방식으로 학습을 한다.
- 특정 가중치가 비이상적으로 커지는 상황을 방지하고, Weight decay 가능해진다.
- 즉, 전체적으로 가중치를 작아지게 하여 과적합을 방지하는 것.
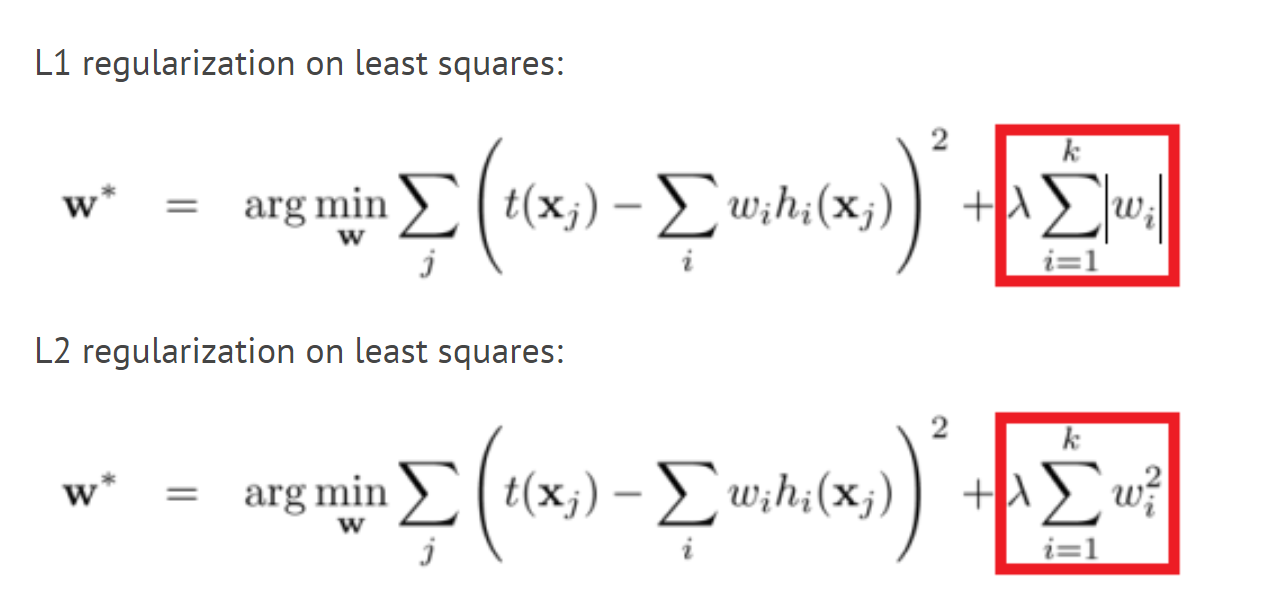
트리 기반 모델의 feature_importances_
- RandomForest, GradientBoosting, XGBoost 등은 각 피처의 중요도를 자동으로 계산한다.
- 중요도가 거의 0에 가까운 피처는 제거 가능하다.
6. 불균형 데이터 처리
언더샘플링
- 대표클래스의 일부만을 선택하고, 소수클래스는 최대한 많은 데이터를 사용하는 방법이다.
- 이때 언더 샘플링된 대표클래스 데이터가 원본 데이터와 비교해 대표성이 있어야 한다.
오버샘플링
- 소수 클래스의 복사본을 만들어 대표클래스의 수만큼 데이터를 만들어주는 것이다.
- 똑같은 데이터를 그대로 복사하는 것이기 때문에 새로운 데이터는 기존 데이터와 같은 성질을 갖게 된다.
두가지를 방법을 사용하여 데이터 비율을 맞추면 정밀도가 향상된다.
7. 텍스트 데이터 처리 (NLP)
Preprocessing Pipeline
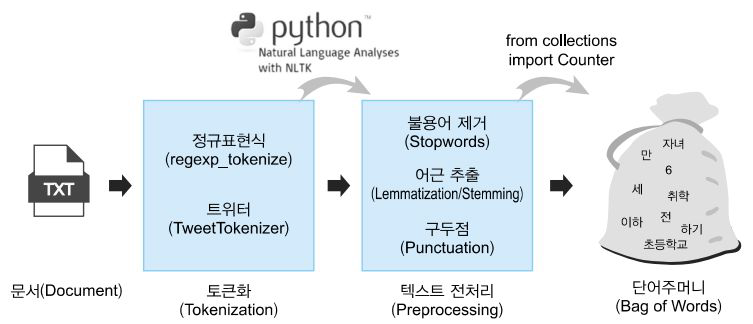
보통 텍스트 데이터는 컴퓨터가 이해할 수 있는 단어로 임베딩한다.
1) 토큰화
- 주어진 데이터를 토큰이라 불리는 단위로 나누는 작업이다.
- 토큰이 되는 기준은 다를 수 있다 (어절, 단어, 형태소 등등)
- 종류 : Character-based Tokenization , Word-based Tokenization , Subword-based Tokenization 등
딥러닝 관점에서 이 단어의 의미를 밀집 벡터로 표현하기 위해서 단어를 사전화 하는 게 중요하다.
추후에 토큰화를 통해서 단어 임베딩을 만드는데 어떻게 토큰화하는 게 성능과 학습에 큰 영향을 주기 때문이다.
주의사항
- 구두점이나 특수 문자를 단순히 제외하면 안 되는 경우, 이를 무시하면 데이터의 의미가 왜곡될 수 있다.
- ex) $100,000에서 $ 기호는 금액임을 나타낸다. 만약 ‘$’ 기호를 삭제하면 ‘100000’이라는 숫자만 남아 금액인지 다른 의미인지 구분하기 어려워짐
- 따라서 토큰화 시 구두점이나 특수 문자가 문맥에서 어떤 역할을 하는지 파악하고, 필요에 따라 이를 유지하거나 별도의 처리를 해야 한다.
- 줄임말과 띄어쓰기는 원래 형태를 되살려야 정확한 의미가 전달된다.
- 문장 토큰화 시 단순히 마침표만을 기준으로 나누면 안 되는 경우
- “서버에 들어가서 로그 파일 저장하고 메일로 결과 좀 보내줘. 그러고 나서 점심 먹으러 가자.” => 여기서 “결과 좀 보내줘. “는 하나의 의미 단위이지만, 이 문장을 단순히 마침표를 기준으로 나누면 두 개의 독립적인 문장으로 잘려 의미가 흐려질 수 있다.
한국어 토큰화의 어려움
영어와는 달리 한국어에는 조사라는 것이 존재한다.
같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식할 수 있다. 그리고 한국어는 띄어쓰기가 영어보다 잘 지켜지지 않는다.
그래서 형태소 단위의 토큰화가 필요하다.
이를 위한 형태소 단위의 Tokenization tools들이 있다.
ex) KoNLPy, SentencePiece(구글)
구글의 SentencePiece는 음절과 단어사이, 형태소와 단어사이의 subword라는 개념이 있는데 그걸 나눠주는 툴이다.
2) 정제
코퍼스 내에서 토큰화 작업에 방해가 되거나 의미가 없는 부분의 텍스트, 노이즈를 제거하는 작업이다.
노이즈는 특수 문자 같은 아무 의미도 갖지 않는 글자들을 의미하기도 하지만, 분석하고자 하는 목적에 맞지 않는 불필요한 단어들을 말한다.
불용어(Stop words)
- 자주 등장하지만 자연어를 분석하는 것에 있어 큰 도움이 되지 않는 단어이다.
- 갖고 있는 말뭉치 데이터에서 최대한 유의미한 단어(토큰)를 선별하기 위해 불용어는 제거하는 것이 좋다.
- 전처리 시 불용어로 취급할 대상을 정의하는 작업이 필요한데 NLTK에서는 여러 불용어를 사전에 정의되어 있다.
- ex) “아”, “아이고”
3) 정규화
정규화를 다르게 말하면 통일성 부여라고도 한다.
어간 추출(Stemming)
- 말뭉치 데이터에서 단어를 줄일 수 있는 정규화 방법 중 하나이다.
- 단어에서 개념적 의미를 갖는 어간만 추출하는 방법이다.
- ex) 먹었다, 먹을 -> 먹다
표제어 추출(Lemmatization)
- 말뭉치 데이터에서 단어를 줄일 수 있는 정규화 방법 중 하나이다.
- 단어를 기본 사전형으로 추출하는 방법이다
- ex) am -> be
4) 인코딩
Bag-of-Words (BoW)
- 문서를 단어별로 잘게 잘라서 단어별 빈도수를 체크하는 방식이다.
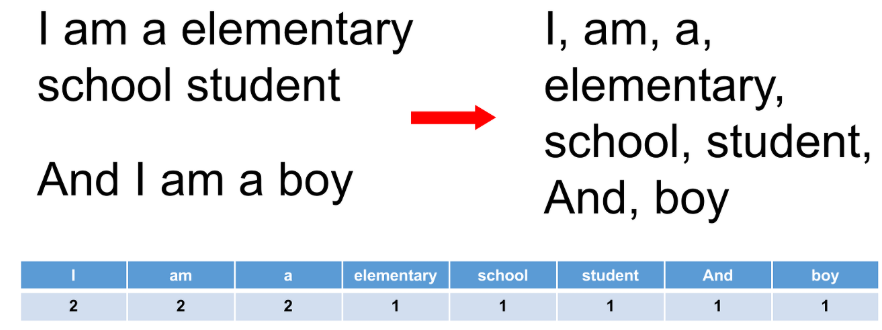
- 이 때 위의 표를 토대로 문장 “And I am a boy”를 임베딩 하면 [1, 2, 2, 2, 1]가 되는데 이를 ‘카운트 벡터’라고한다.
- 주제가 비슷한 문서라면 사용하는 단어들의 빈도가 비슷할 것이다.”라는 철학에서 시작됐다.
TF-IDF
- 그런데 위와 같은 ‘카운팅 방식’의 가장큰 문제점은 해당 단어가 많이 나타났다 하더라도 문서의 주제를 가늠하기 어려운 경우이다.
- ‘을’, ‘를’, ‘이’, ‘가’와 같은 조사들은 우리가 사용하는 문서들에 많은 부분을 차지하지만 문서의 유의미한 의미는 없다.
- 이러한 단점을 보완하기 위해 제안된 기법이 ‘TF-IDF’이다.
- 용어
- TF(Term Frequency) : 어떤 단어가 특정 문서에 얼마나 많이 쓰였는지의 빈도
- DF(Document Frequency) : 특정 단어가 나타난 문서의 수
- IDF(Inverse Document Frequency) : 전체 문서 수 N을 해당 단어의 DF로 나눈 뒤 로그를 취한 값.즉 해당 단어가 얼마나 얼마나 “희귀하게” 쓰였는지를 나타내는 지표
=> TF-IDF나 BoW, 원핫 인코딩는 고전적인 텍스트 벡터화 방법이고, 임베딩이 나오기 전까지는 자연어처리에 많이 쓰였다.
5) 임베딩
워드 임베딩?
- 단어들 단어들 사이의 의미적 관계를 포착할 수 있는 밀집(dense)되고 연속적/분산적(distributed) 벡터 표현으로 나타내는 방법이다.(표현을 학습 시키는 것)
- 원-핫 인코딩에선 비슷한 단어가 완전히 독립적인(무관한) 벡터로 표현되었지만, 워드 임베딩에서는 두 단어의 벡터가 공간상 서로 가깝게 위치하며, 이를 통해 의미적 유사성을 반영할 수 있다.
- 대표적인 기법
- Word2Vec : 각 단어와 그 주변 단어들 간의 관계를 예측한다는 것. 단어의 표현을 간단한 인공 신경망을 이용해 학습한다.
- 1) Skip-grams(SG) 방식 => 중심 단어를 통해 주변 단어들을 예측하는 방법
- 2) Continuous Bag of Words (CBOW) 방식 => 주변 단어들을 통해 중심 단어를 예측하는 방법
- Word2Vec : 각 단어와 그 주변 단어들 간의 관계를 예측한다는 것. 단어의 표현을 간단한 인공 신경망을 이용해 학습한다.
사전 학습된 임베딩 모델
- Word2Vec, FastText, BERT 등등
- 각 단어/문장을 고차원 벡터로 표현한다.
- 문장 평균, CLS 토큰 등을 사용해 문장 레벨 피처를 추출한다.
- 임베딩은 단순한 숫자화가 아니라 단어·문장·이미지·그래프 등 입력 데이터를 ‘의미를 잘 담은 벡터 공간’으로 학습한 결과물이다. (by Representation Learning)
Encoding vs Embedding
헷갈릴 수도 있는 개념이니 짚고 넘어 가보자.
위에서 본 인코딩, 임베딩 둘다 데이터를 벡터로 바꾼다는 공통점은 있다.
- 인코딩
- 데이터를 다른 표현 형태로 바꾸는 기술 전체를 말한다.(데이터 포맷을 바꿔 표현하는 모든 과정)
- 의미가 보존되지 않는다.
- 임베딩
- 의미를 보존하며 벡터 공간에 매핑하는 인코딩의 한 종류라고 볼 수 있다.
- 의미가 보존된다.