Retrieval Augmented Generation (RAG)
Information Retrieval (IR)
- 검색 질의와 가장 관련성 높은 정보를 제공하는 것이 목표임
- IR 활용 예시
- 웹 서치, 아이템 서치
- 추천시스템
- 검색 증강 생성
RAG(Retrieval-Augmented Generation)
- RAG란?
- 검색 증강 생성(RAG)은 외부 데이터 소스를 연결하여 대규모 언어 모델의 출력을 향상시키는 기술이다.
- LLM이 비공개 또는 도메인별 데이터에 접근하고 환각 문제를 해결하는 데 적합하다. => 추천 시스템 or AI 챗봇 시스템과 같은 다양한 GenAI 애플리케이션을 구동한은 데 널리 사용되어 왔다.
- 등장 배경
- ChatGPT를 전문적으로 사용하고자 할 때의 문제점
- 최신 정보에 대한 학습 미비
- 개인이나, 회사의 내부데이터에 대한 학습 미흡 - 정리본 넣으면 OpenAI사의 DB에 저장되기 때문에 기밀정보 유출 가능성, Hallucination…
- ChatGPT를 전문적으로 사용하고자 할 때의 문제점
- 기대 효과
- 최신 정보 기반 답변 가능, 검색 기능 활용하여 답변 가능
- 문서를 회사 내부 DB에 저장
- 가능 → DB에 내용 축적, 원하는 정보 검색 가능, 내부 데이터 참고해서 답변 가능
- 답변에 대한 출처를 역으로 추적해서 검증하는 방식 통하여 Hallucination 줄일 수 있다.
⇒ DB 기반 답변을 통해 도메인 특화 챗봇 생성이 가능하다.
- 거대 언어모델이 보유한 지식은 금세 시대에 뒤쳐지며 갱신이 어렵지만 Datastore는 쉽게 업데이트가 가능하며 확장성도 만족함
- 기업 내부와 같은 보안 정보는 언어모델 학습에 활용되지 않는다 –> 이럴때 RAG가 유용할 수 있음
- ChatGPT 내장 RAG
- 업로드된 문서를 기반으로 답변하는 것에 사용되고 있음.
- 그 과정이 블랙박스로, 공개되지 않으며 컨트롤 불가능 ⇒ 문서를 지피티가 잘 참고할 수 있는 형태로 변경해주는 것이 최선이다.
- Retrieval-augmented LM
- 추론 시 외부 데이터 저장소를 불러와 활용하는 언어모델
- 구성요소
-
Datastore
-
최소 수십억에서 수조 단위의 토큰으로 구성
-
라벨링된 데이터셋이 아님
-
지식 베이스와 같은 구조화된 데이터가 아님
-
-
Query
- 검색 질의 / Retrieval input → 언어 모델의 질의와 같아야 하는 것은 아님
-
Index
-
문서나 단락과 같은 검색 가능한 항목들을 체계적으로 정리하여 더 쉽게 찾을 수 있도록 하는 것
-
각 정보 검색 메서드는 인덱싱 과정에서 구축된 인덱스를 활용해, 쿼리와 관련 있는 정보를 식별함
-
-
Language Model
-
RAG process
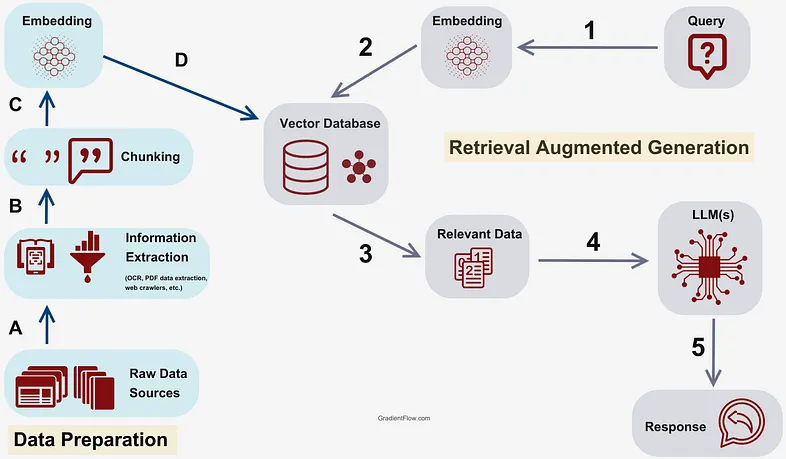
- Document load
- 문서를 로드하고 초기 처리
- Text Splitter
- 로드된 문서를 처리 가능한 작은 단위로 분할
- Embedding
- 각 문서 또는 문서의 일부를 벡터 형태로 변환하여 문서의 의미를 수치화
- Vector Store
- 임베딩된 벡터들을 데이터베이스에 저장 → 요약된 키워드를 색인화
- Retriever
- 질문이 주어지면 이와 관련된 벡터를 벡터 데이터베이스에서 검색
- Prompt
- 검색된 정보를 바탕으로 언어 모델을 위한 질문을 구성
- LLM(Large Language Model)
- 구성된 프롬프트를 사용하여 언어 모델이 답변을 생성
- Chain 생성
- 이전의 모든 과정의 하나의 파이프라인으로 묶어주는 Chain 을 생성
Retriever 종류
Sparse Retriever (어휘적 유사도 기반)
- 전통적인 정보검색(IR) 기법으로 쿼리와 문서 간의 정확한 용어 일치(즉, 어휘적 유사도)에 기반함
- ex) TF-IDF, BM-25
- TF-IDF : 문서 안에서 자주 등장하는 단어는 중요(TF) / 하지만 너무 많은 문서에 등장하는 단어들은 덜 중요(IDF)
- 장점
- 단순성 - 구현과 이해가 비교적 쉬움
- 효율성 - inverted index 구조 덕에 빠른 검색과 효율적인 질의 처리가 가능함
- 투명성 - 검색 결과가 보통 해석 가능하며 용어 매칭에 기반하기 떄문에 설명이 명확함
- 단점
- 제한된 의미 이해
Dense Retriever (의미적 유사도 기반)
- 쿼리와 문서를 표현하기 위해 dense vector를 활용해 의미적 유사도에 기반함
- ex) DPR, Contriever …
- 임베딩 모델
- 단어/문장의 의미를 표현할 수 있음
- BI encoder
- BI-encoder retriever은 대조 학습을 통해 학습되며 이는 쿼리가 긍정적인 문서와 가깝게 유지되도록 하고 부정적인 문서에서는 멀어지도록 유도함
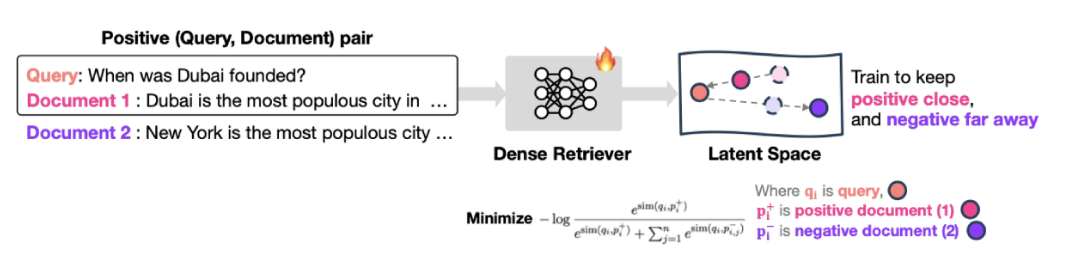
- BI-encoder retriever은 대조 학습을 통해 학습되며 이는 쿼리가 긍정적인 문서와 가깝게 유지되도록 하고 부정적인 문서에서는 멀어지도록 유도함
- Cross-encoder
- 두 개의 텍스트를 하나의 시퀀스로 결합함
- self-attention을 통해 모든 쿼리와 문서 토큰이 완전히 상호작용할 수 있어 BI-encoder보다 더 높은 정확도를 얻을 수 있음
- 하지만 모든 쿼리-문서 쌍을 개별적으로 모델에 입력해야 하므로, 계산 비용이 크고 처리속도가 느리다는 단점이 있음

- BI vs Cross
- BI-encoder는 두 문장을 따로 인코딩함 => 매우 빠르고 대규모 데이터베이스 검색에 적합하지만 정확도는 낮음
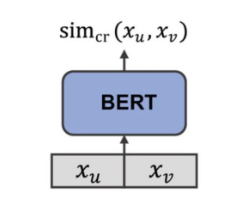
- Cross-encoder는 두 문장을 함께 처리함 => 매우 느리지만 세밀한 상호작용을 포함하기 때문에 정확도가 높음
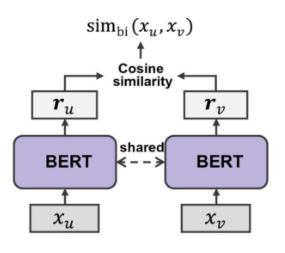
- BI-encoder는 두 문장을 따로 인코딩함 => 매우 빠르고 대규모 데이터베이스 검색에 적합하지만 정확도는 낮음
- dnese retriever의 장단점
- 장점
- 동의어나 다양한 표현을 더 효과적으로 처리 가능
- 복잡한 쿼리와 긴 검색 쿼리의 이미를 더 잘 포착 가능하다
- 단점
- 모델 학습에 시간과 계산 자원이 많이 필요함
- 블랙박스처럼 작동할 수 있어 특정 문서가 왜 검색되었는지 해석하기 어려움
- 성능은 학습 데이터의 품질이나 모델 변경에 크게 영향을 받음
- 장점
Challenges of RAG
- RAG의 결과는 검색 모델 성능에 의존한다. 즉, 검색 노이즈에 취약하다. 정확하지 않은 유사 정복 ㅏ언어모델에 답하는 것을 방해할 수 있음
- Transformer 어텐션 레이어에서 컨택스트 내 단어 벡터들이 가중합이 되어 다음 단어를 예측하는데 활용된다. 이때 가중치는 0~1 사이 값이라 컨텍스트 정보를 무시하는 것이 어렵다
=> 즉, 정보검색을 사용하는 것만으로는 사실의 정확성 보장이 어렵다
- LLM의 사전지식과 컨텍스트 간의 충돌 발생
- solution1) 컨텍스트 위에서 grounding 학습 강화

- solution2) 컨텍스트가 없을 때 답변 회피/거절 학습

- solution1) 컨텍스트 위에서 grounding 학습 강화
- 복잡한 추론 필요할 때 & 문서가 명확한 사실에 대한 오류를 포함할 때