LangChain 실습하면서 뜯어보기
본 포스팅은 위 링크를 참고하여 작성하였습니다.
LangChain, LangGraph, LangSmith란?
우선 실습을 하기 위해 필요한 requirements는 다음과 같다.
ipykernel
notebook
langchain=1.0.2
langchain-core=1.0.1
langchain-openai=1.0.1
langchain-google-vertexai=3.0.2
langchain-community=0.4.1
langgraph-checkpoint-sqlite==3.0.0
ollama
numpy=2.3.3
pandas=2.3.3
python-dotenv
ddgs
conda를 통해서 가상 환경을 만들고 실습을 진행했다.
# llm api 호출을 위한 api key
OPENAI_API_KEY=
# 환율 API key. 실습을 위해 필요한 외부 api가 있다면 key를 여기에 추가하세요.
EXCHANGE_RATE_API_KEY=
# langsmith api key. metrics 및 traces 저장 및 조회에 사용됩니다.
LANGSMITH_API_KEY=
# langsmith 설정
LANGSMITH_PROJECT=
LANGSMITH_TRACING=true
OPENAI_API_KEY는 openAI 키를 받아서 작성하면 된다.
EXCHANGE_RATE_API_KEY는 생략이 가능하다.
LANGSMITH_API_KEY는 Langsmith 사이트에 들어가서 가입 후, 발급 받으면 된다.
LANGSMITH_PROJECT는 원하는 프로젝트명을 작성한다.
LangChain의 현재 최신 버전은 1.0이다.
0버전과 문법 및 객체 구조가 매우 달라졌다고 한다. 활용 및 개발시에 GPT의 도움보다는 공식 문서를 기반으로 개발하기를 추천한다.
단일 Model 호출
먼저 Agent 없이 단일 모델을 호출해보자.
from langchain.chat_models import init_chat_model
model = init_chat_model(
model = "openai:gpt-5-nano",
temperature=0.8, # 응답의 창의성
max_tokens=2000, # 최대 토큰 수
timeout=20, # 요청 제한 시간(초)
max_retries=2, # 요청 실패 시 재시도 횟수
)
nano는 추론 능력이 좀 부족하긴 하다. 좀 더 능력이 높은 걸 원하면 mini를 써보는 것도 좋다.
GPT-5 계열 모델들은 temperature 파라미터를 지원하지 않지만, Langchain에서는 일관된 인터페이스를 제공하기 때문에 오류가 발생하지 않는다.
response = model.invoke('안녕')
pprint(response)
모델, angent 실행이나 호출은 모두 .invoke() 함수를 통한다고 생각하면 된다.
여기서 모델이 보내준 실제 답변 내용만 출력하려면 response.content로 해주면 된다.
Agent 생성
고작 위의 단일 모델을 호출하려고 LangChain을 쓰는 게 아니다.
랭체인은 에이전트를 만들 때 진가를 발휘한다.
from langchain.agents import create_agent
agent = create_agent(
model=model, # 사용할 LLM 모델을 미리 초기화(init)한 후 인자로 전달
tools=[], # tool은 필수 인자지만, 빈 리스트를 전달하면 아무 tool도 없는 Agent를 생성할 수 있다.
system_prompt="You are a helpful assistant.", # Agent의 시스템 프롬프트.
middleware=[], # Agent의 동작 사이에 발생하는 요청이나 응답을 가로채서 처리하는 고급 기능이다.
)
실제 답변 내용만 출력하려면 messages 리스트의 마지막 요소의 content 속성을 참조하면 된다. response["messages"][-1].content과 같이.
# Agent에 전달할 메시지 객체를 생성
from langchain.messages import HumanMessage
messages = [
HumanMessage(content="오늘 서울 날씨는 어때?"),
]
# Agent에 대한 invoke는 모델 invoke와는 다르게 dictionary 형태의 입력을 받으니 주의!
response = agent.invoke({"messages":messages})
messages = [
{"role": "user", "content": "오늘 서울 날씨는 어때?"},
]
=> 이렇게 메세지 객체는 딕셔너리 형태로 넣어줘도 된다.
인자 tools 의 기능
위에서 만든 Agent는 별다른 기능이 없으니 단일 모델 호출과 별로 다를 게 없다.
랭체인 실습을 해보면서 이 tools 인자 옵션이 랭체인의 강력한 기능이라고 느꼈다.
내가 원하는 커스텀한 함수, 원하는 tools들을 리스트업해서 넘겨주고 이걸 agent가 자율적으로 사용할 수 있게 하는 것. 현재 기획중인 서비스에 적용하기가 아주 유용할 것 같다.
커스텀 함수를 간단히 만들어서 적용해보자.
# tool 정의를 위해 필요한 모듈입니다.
from langchain.tools import tool
# 커스텀 tool 생성
@tool # 데코레이터를 사용하여 tool로 등록함.
def calculator(num_1:int, num_2:int) -> int: # typehint는 Agent가 tool의 입출력 형식을 이해하는 데 도움을 준다. 안정적인 작동을 위해 반드시 작성하는게 좋음.
"""입력받은 두 수의 덧셈을 반환합니다.""" # docstring은 tool의 설명으로 사용된다. Agent가 tool을 선택하는 데 도움을 줌.
return num_1 + num_2
이런식으로 커스텀 함수를 만들어서 인자로 넘겨줘도 되지만,
langchain-community에 통합된 외부 tool 사용할 수도 있다.
라이브러리를 통해 제공되는 외부 tool들을 langchain-community에서 통합하여 사용할 수 있다. 외부 tool 보러가기
langchain community에서 통합되어 있는 외부 tool의 목록을 확인해보자.
import importlib, pkgutil
package = importlib.import_module("langchain_community.tools")
for mod in pkgutil.iter_modules(package.__path__):
print(mod.name)
목록은 다음과 같다.
여기서 ddg_search를 한 번 써보자.
# duckduckgo는 api key 없이도 사용할 수 있는 웹 검색 도구이다.
import langchain_community.tools.ddg_search
# duckduckgo 검색 tool의 속성을 확인하여 검색 기능 호출 방법을 알아보자.
print(dir(langchain_community.tools.ddg_search))
확인한 출력중에 duckduckgo의 검색 기능을 import 하고 tool 인스턴스를 생성하자.
from langchain_community.tools.ddg_search import DuckDuckGoSearchRun
ddg_search_tool = DuckDuckGoSearchRun()
이렇게 커스텀한 함수 + 외부 tool을 다음과 같이 Agent에게 전달해서 사용이 가능하다.
# nano 모델은 Agent로 사용하기엔 너무 성능이 낮아 무한 루프 등 의도하지 않은 동작이 발생할 수 있으므로 mini 모델로 변경함.
model = init_chat_model("openai:gpt-5-mini")
# agent 생성 및 tool 전달
agent = create_agent(
model=model,
tools=[calculator, ddg_search_tool], # 앞서 만든 두 가지 tool을 리스트로 전달.
)
모델 vendor들이 제공하는 tool을 모델에 바인딩
LLM API를 제공하는 vendor들은 모델에서 곧바로 이용할 수 있는 tool을 함께 서비스하고 있다.
vendor들이 제공하는 tool을 사용할 때는 주의해야 한다.
현재 버전에서 Agent를 통하지 않고 단일 Model을 직접 호출해야만 사용할 수 있는 기능입니다.
Agent를 활용하는 경우 사용할 수 없는 방법이다.
설계가 복잡해지고 세밀한 구조 설계, 유지보수를 어렵게 만드는 방식이니 사용하면 안된다.
개념만 이해하고 넘어가보자.
from langchain_openai import ChatOpenAI
# 객체 생성
llm = ChatOpenAI(
temperature=0.5,
model_name="gpt-5-mini", # 모델명
)
# 질의내용
question = "대한민국의 수도는 어디인가요?"
# 질의
print(f"[답변]: {llm.invoke(question)}")
# 모델 vendor들이 제공하는 tool을 모델에 바인딩하기 위해 필요한 모듈
from langchain_openai import ChatOpenAI
# OpenAI 전용 Model 초기화 메서드
# OpenAI 모델에서 제공하는 tool을 바인딩하기 위해서는 모델 초기화시 ChatOpenAI 클래스를 사용해야 함
model = ChatOpenAI(
model="gpt-5-mini",
)
# ChatOpenAI 모델 인스턴스에 커스텀 tool을 바인딩하자.
# 모델이 사용할 tool 리스트를 정의.
# 딕셔너리 형태의 web search tool은 openai가 제공하는 tool이고,
# calculator는 위에서 직접 만든 커스텀 tool
# ddg는 웹 검색 역할이 중복되므로 제외함.
tools = [{"type": "web_search"}, calculator]
model_with_calculator = model.bind_tools(tools)
# model을 호출
response = model_with_calculator.invoke(
"올해 11월에 한국에서 개봉하는 주요 영화 3개만 알려줘. 그리고 12311 더하기 112455는 몇이야?",
)
# 추론 과정에서 커스텀 tool이 호출되면, 추론 루프를 멈추고 AIMessage를 반환.
# Agent가 아닌 단일 모델에 대한 invoke이기 때문에 커스텀 tool 호출에는 대응하지 못하기 때문이다!
# 별도로 다시 invoke를 체이닝하는 등 추가 코드가 필요하나, 너무 구린 방식이니까 그냥 넘어감.
pprint(response)
메모리
맥락을 유지하고 개인화된 응답을 제공하기 위해 checkpointer 객체에 메모리를 저장할 수 있다.
checkpoint 모듈로 관리한다.
단기 메모리
세션이 유지되는 동안 대화 기록을 저장해보자.
세션이 종료되면 이 메모리는 사라지고 복구가 불가능하다.
# 쓰레드 내 단기 기억 저장용 객체를 생성하기 위한 모듈
from langgraph.checkpoint.memory import InMemorySaver
# InMemorySaver 객체를 포함하여 Agent 생성
agent = create_agent(
model=model,
tools=[calculator, ddg_search_tool], # 앞서 만든 두 가지 tool을 리스트로 전달
checkpointer=InMemorySaver(),
# middleware는 메모리 관련 처리가 아닌가?
# middleware 같은건 예를 들어 랭체인 할때 답낼때 루프같은거 돌때 루프 도는 횟수 제한하거나,
# 워낙 기능이 많아서 공식 문서를 보는 것을 추천
)
메세지 객체와 리스폰스 객체를 정의하는 과정은 위와 같다.
리스폰스 객체 생성시 configurable 을 넣어주어 추가한다ㅣ
response = agent.invoke(
{"messages":messages},
# 설정값으로 대화 기록을 저장할 쓰레드 번호를 함께 넘겨줘야 함
# 대화 기록이 들어 있는 쓰레드는 세션 종료시 삭제됨
{"configurable": {"thread_id": "1"}},
)
장기 메모리
위에서 InMemorySaver로 만든 기억은 세션이 사라지면 함께 없어진다.
사용자가 앱을 껐다 켜고, 기존에 대화를 나눴던 세션에 들어왔을 때도 기억이 남아있으려면, 대화 기록을 영속적으로 저장해야 한다.
sqlite DB에 대화 기록을 저장할 수 있는 Agent를 만들어보자.
# sqlite용 checkpointer 객체 생성을 위한 모듈
from langgraph.checkpoint.sqlite import SqliteSaver
# checkpointer 객체 생성
checkpointer = SqliteSaver.from_conn_string("checkpoints.db")
# DB는 with문 안에서만 연결되어 있음.
with SqliteSaver.from_conn_string("checkpoints.db") as checkpointer:
# 테이블이 없을 경우 생성
checkpointer.setup()
# Agent 객체 생성
agent = create_agent(
model=model,
tools=tools,
checkpointer=checkpointer,
)
# 실행 후, sqlite DB에 대화 기록이 잘 저장되었는지 확인해보자.
# Agent에 전달할 메시지 객체를 생성
messages = [
HumanMessage(content="langchain의 설계 철학에 대해 알려줘."),
]
# Agent invoke
response = agent.invoke(
{"messages":messages},
{"configurable": {"thread_id":1}},
)
# 출력
pprint(response)
실제로 서비스화 해서 고객별로 대응할 때, 고객별로 저장을 어케하는지 응용해보면 좋을 듯하다!
추가적으로 단기 메모리든 장기 메모리든, 모델은 쌓여 있는 모든 대화기록을 input받아 대답한다.
따라서 세션 내 대화가 길어질수록 token 사용량이 급격히 늘어나고, 모델이 한 번에 처리할 수 없는 양이 되면 오류를 발생시킨다.
오래된 메시지를 제거하거나 요약하는 등의 방법으로 제어해야 하는데, 미들웨어를 통해 이를 관리할 수 있다.
미들웨어
미들웨어를 통해 에이전트의 추론 과정 중간에 개입하여 내부 동작을 커스터마이징할 수 있다.
Agent를 세부적으로 커스터마이징하기 위한 대부분의 작업이 미들웨어를 통한다.
- 대화 기록 요약
- 동작 중 사용자 입력 대기
- 특정 모델 또는 tool에 대한 호출 제약
- fallback
- PII(개인식별정보) 처리 등
서비스 개발시에는 공식문서를 참고해서 필요한 걸 쓰면 된다.
대화 기록 요약
간단하게 대화 기록 요약 미들웨어를 실습할 것이다.
대화가 지속될 때 context가 무한히 늘어나지 않도록 이전 대화 기록을 요약해서 전달해보자.
# 미들웨어에서 대화 기록을 요약하기 위해 사용되는 모듈입니다.
from langchain.agents.middleware import SummarizationMiddleware
# 요약하려면 기록이 있어야 하니까, 단기 메모리를 만들어 줍니다.
from langgraph.checkpoint.memory import InMemorySaver
# model 정의
model = init_chat_model(
model="openai:gpt-5-mini",
max_tokens=8000,
)
# 사용할 middleware 객체를 미리 정의
middleware_summarize = SummarizationMiddleware(
model=model, # 요약하는 데에 쓸 모델. 물론 Agent 모델과 다른 걸 써도 됨
max_tokens_before_summary=1000, # 모델이 처리해야 할 토큰 수가 임계치를 넘으면, 요약을 먼저 수행.
messages_to_keep=1, # 요약에 포함시키지 않을 최근 메시지의 수를 결정함. 너무 낮게 설정하면 최근 대화에 대한 맥락이 소실되니 주의!
# summary_prompt="요약할 때 이렇게 저렇게 해줘.. 커스터마이징 프롬프트 사용 가능"
)
# Agent 생성
agent = create_agent(
model=model,
checkpointer=InMemorySaver(), # 단기 메모리를 저장할 checkpointer 객체 지정
middleware=[middleware_summarize, ], # 위에서 정의한 middleware를 Agent에게 전달함.
)
위의 코드처럼 middelware도 에이전트를 생성할 때 tools를 넘겨줬던 것처럼 넘겨주면 된다.
# Agent가 요약을 실행하고 있는지 응답을 확인해보자.
# Agent에 전달할 메시지 객체를 생성함.
messages = [
HumanMessage(content="뮤지컬 Wicked의 내용을 Elphaba 입장에서 서술해줘. 그리고 그 내용을 기반으로 Elphaba를 연기할 때 신경써야 할 포인트들을 짚어줘."),
]
# Agent 호출
response = agent.invoke(
{"messages":messages},
{"configurable": {"thread_id": "1"}}, # 단기 메모리를 저장할 쓰레드 번호를 전달.
)
# Agent 호출을 반복하여 대화 기록을 쌓아 보자.
messages = [
HumanMessage(content="Glinda를 어떤 감정으로 바라보는게 좋을까?"),
]
response = agent.invoke(
{"messages":messages},
{"configurable": {"thread_id": "1"}},
)
# 세 번째 호출!
messages = [
HumanMessage(content="도와줘서 고마워. 연기 잘 해볼게."),
]
response = agent.invoke(
{"messages":messages},
{"configurable": {"thread_id": "1"}},
)
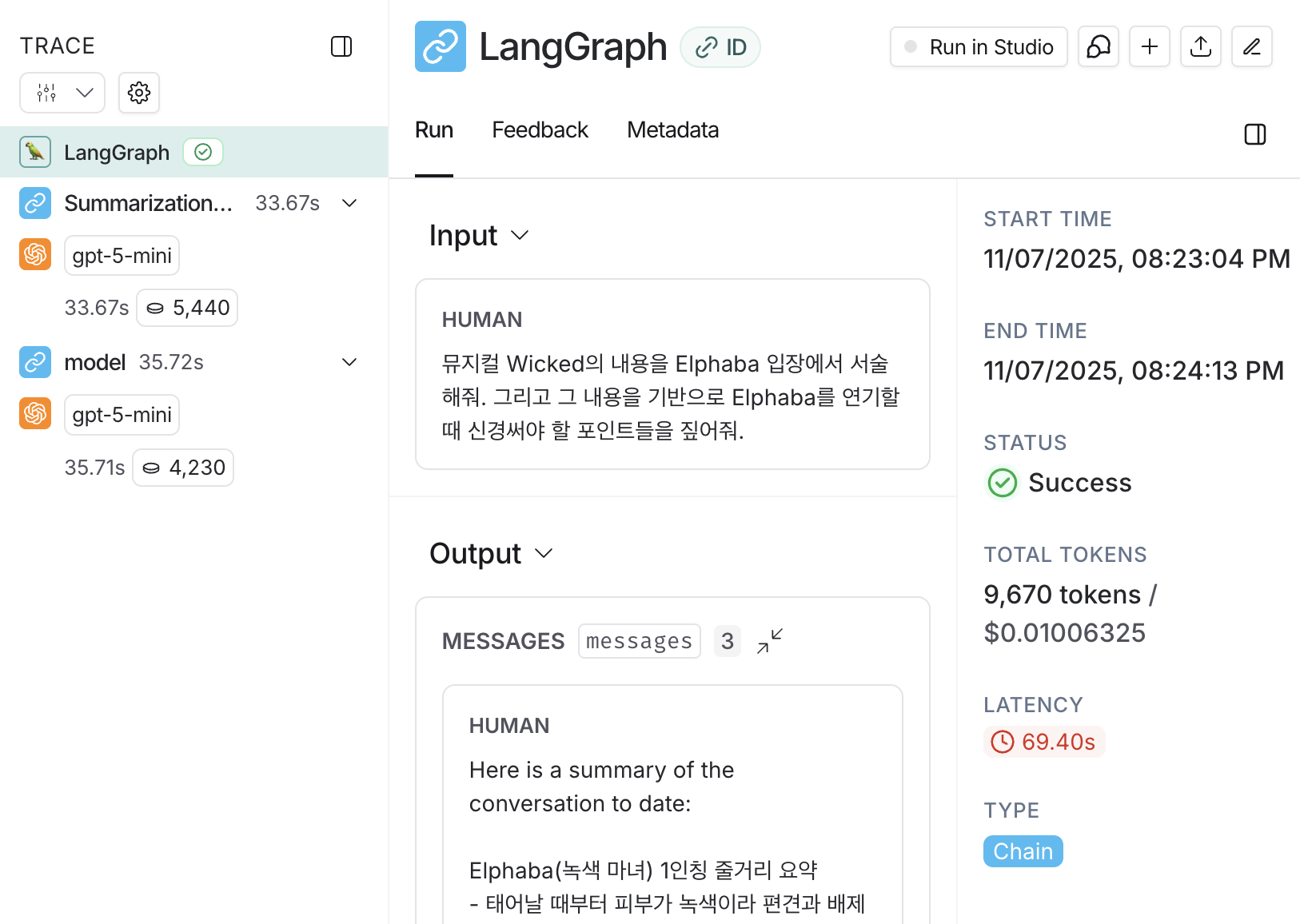
# langsmith로 가서, middleware가 어떻게 호출되었는지 꼭 확인해보기
pprint(response)
=> InMemorySaver()를 통해서 메세지를 계속 재정의해도 마치 append하는 것처럼 메모리가 쌓이고 있는 것이다.
- LangSmith에서 확인
스트리밍
Agent의 반복적인 추론으로 인한 지연 시간은 UX를 크게 저하시킨다.
출력을 점진적으로 표시하는 스트리밍 기능을 통해 보완해보자.
실제로 지연 시간은 줄어들지 않지만, 사용자 입장에서 시간의 공백이 느껴지지 않도록 하게 해준다.
OpenAI API는 스트리밍 기능 사용을 위해 기관 인증을 요구하므로 지금은 사용할 수 없지만, 로컬 LLM을 통해서 테스트해보자.
from langchain_community.chat_models import ChatOllama
# Ollama 데스크탑 앱을 설치하고, 터미널에서 사용할 모델(gemma3)를 미리 다운받아야 함
# ollama pull gemma3
# 모델 지정
model = ChatOllama(
model="gemma3",
streaming=True,
)
# Agent 생성 및 tool 전달
agent = create_agent(
model=model,
)
# Agent에 전달할 메시지 객체를 생성.
messages = [
HumanMessage(content="Who is the best football player in history?"),
]
실제로 스트리밍 출력을 눈으로 확인하기 위해 내용을 파일에 저장해보겠다.
# ollama 실행 및 gemma3 모델 pull이 되어있지 않으면 여기서 오류가 발생
with open("stream_output.txt", "w", encoding="utf-8") as f:
# agent.stream()으로 호출
for token, metadata in agent.stream(
{"messages": messages}, # HumanMessage 객체 전달
stream_mode="messages", # 스트림으로 받을 단위 설정
):
# 노트북 셀 출력
print(f"node: {metadata['langgraph_node']}")
print(f"content: {token.content_blocks}")
# 파일에 저장
f.write(f"node: {metadata['langgraph_node']}, ")
f.write(f"content: {token.content_blocks}")
f.write('\n')
f.flush()
실제로 txt 파일을 확인해보면 스트리밍 되는 모습을 확인할 수 있다.
이렇게 LangChain ver1를 뜯어보고 이해해 봤다.
지금 기획중인 서비스 개발에서 너무 유용한 framework로 잘 사용할 수 있을 것 같고,
다음에는 Agent를 적극적으로 활용해서 LangGraph까지 뜯어봐야 겠다!
재밌당.