파이썬으로 탐색적 데이터 분석(EDA)을 해보자
해당 포스팅에서는 load_wine 데이터를 사용한다.
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
# 데이터 불러오기
df, y = load_wine(as_frame=True, return_X_y=True)
df["quality"] = y

필요한 패키지를 불러오고 시작해야 한다.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme()
EDA란?
데이터 분포, 중앙값·사분위수·상관관계 등을 시각화를 통해 탐색하는 기법이다.
실제 현실의 데이터들은 깔끔하지 않아서 모델링 과정보다, 데이터를 처리하고 정리하는데 더 많은 시간을 쏟을 수 있다.
그만큼 데이터를 정제하는 것은 중요한 과정이고, 그 전에 데이터가 어떤 특성을 가지는지 살펴보는 것이 그 시작이다.
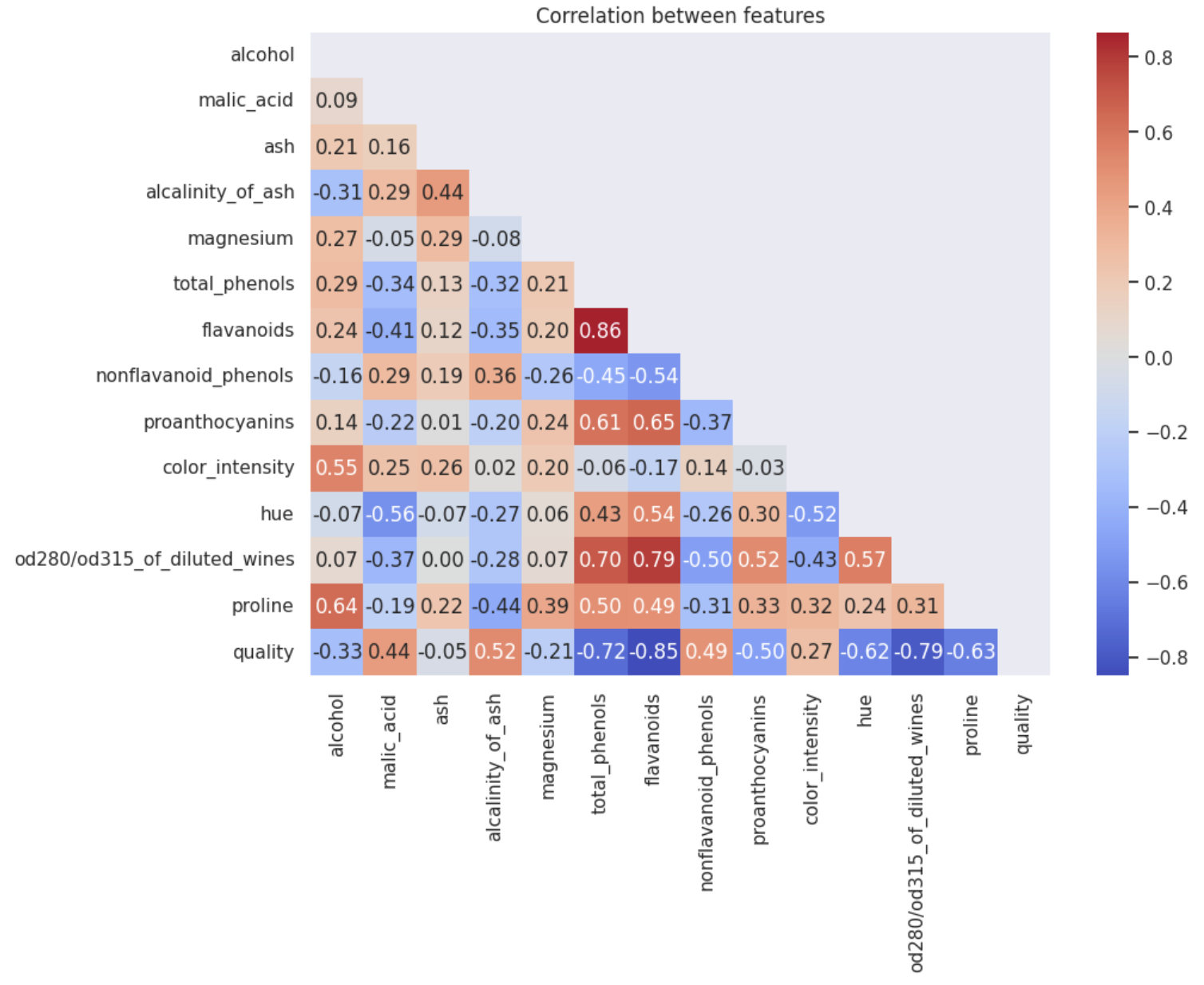
상관관계
# 상관관계 저장
corr = df.corr()
# 그래프 그리기
plt.figure(figsize=(10, 8))
sns.heatmap(
corr,
annot=True,
fmt=".2f",
cmap="coolwarm",
mask=np.triu(np.ones_like(corr, dtype=bool)),
square=True,
cbar=True,
)
plt.title("Correlation between features")
plt.show()
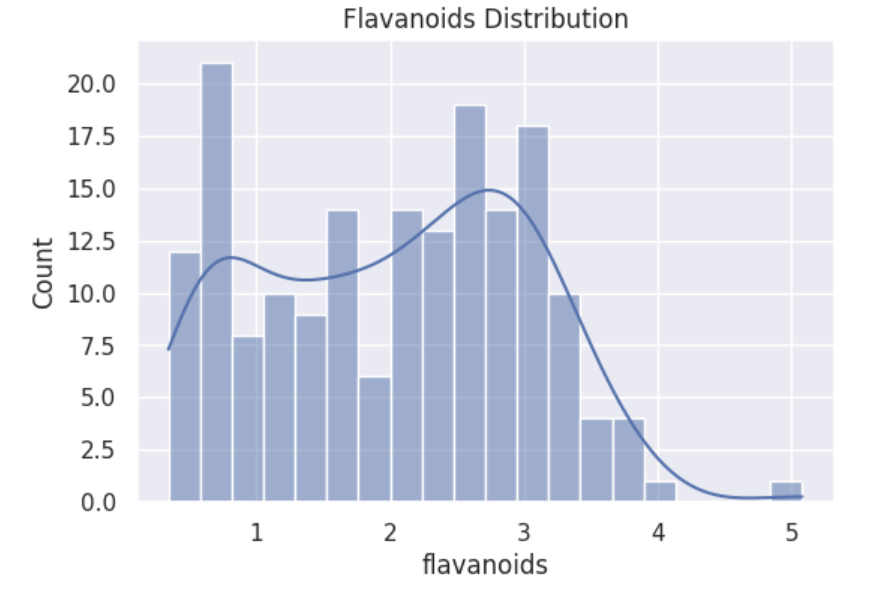
도수 분포표
plt.figure(figsize=(6, 4))
sns.histplot(data=df, x='flavanoids', bins=20, kde=True)
plt.title('Flavanoids Distribution')
plt.show()
산점도
sns.scatterplot(
data=df,
x='flavanoids',
y='total_phenols',
hue='quality',
alpha=0.7
)
plt.show()
이렇게 그래프 한개씩 그리지 말고 한꺼번에 다 그리고 싶다면?
pairplot 을 사용하면 된다.
# 1. 상관관계 행렬 계산
corr = df.corr(numeric_only=True)
# 2. 예를 들어 flavanoids와 상관 높은 feature 4~5개를 선택
# Exclude 'quality' from the top features calculation as it's the target variable
top_features = corr['flavanoids'].abs().sort_values(ascending=False).drop('quality').head(5).index
print(top_features)
# 3. 선택한 feature들과 quality를 함께 pairplot으로 시각화
# Create a new DataFrame with only the selected features and the quality column
plot_df = df[top_features.tolist() + ['quality']]
sns.pairplot(
plot_df,
hue='quality',
palette='mako',
diag_kind='kde'
)
plt.show()
결측치 & 이상치 확인
데이터가 누락되거나 잘못 기입된 경우는 없는지 확인해야 한다.
실제로 데이터를 처리해보시면 이러한 경우가 비일비재하기 때문에 확인하는 것이 필수적이다.
-
결측치 확인 결측치는 데이터가 비어 있는 경우를 말한다.
처리 방법에는 크게 두 가지가 있다.
첫째, 결측치가 있는 행이나 열을 통째로 삭제하는 방법이 있다. 데이터가 충분히 많고 결측이 일부일 때는 유용하지만, 데이터 손실이 클 수 있다.
둘째, 결측 값을 다른 값으로 채우는 방법이 있다. 숫자형 데이터의 경우 평균값, 중앙값, 최빈값으로 채우거나, 시계열 데이터에서는 이전 값이나 다음 값으로 채우는 방법을 쓴다. 더 나아가 머신러닝 모델로 결측치를 예측해 채우는 고급 기법도 있다.
df.isnull().sum() -
이상치 확인 이상치는 다른 데이터와 비교했을 때 값이 너무 크거나 작아서 눈에 띄는 데이터를 말한다.
이상치는 데이터 입력 실수, 측정 오류, 혹은 정말 드문 특별한 경우 때문에 발생할 수 있다.
분석 전에 이런 값을 확인하고, 잘못된 값이면 제거하거나 경계값으로 바꾸고, 의미가 있다면 그대로 두는 것이 좋다.
IQR(사분위 범위)은 이상치를 찾는 대표적인 방법 중 하나이다!
def detect_outliers_iqr(data, column): Q1 = data[column].quantile(0.25) Q3 = data[column].quantile(0.75) IQR = Q3 - Q1 lower_bound = Q1 - 1.5 * IQR upper_bound = Q3 + 1.5 * IQR return data[(data[column] < lower_bound) | (data[column] > upper_bound)] outliers_alcohol = detect_outliers_iqr(df_missing, 'alcohol') print(f"alcohol 이상치 개수: {len(outliers_alcohol)}") # boxplot으로 이상치 확인 sns.boxplot(x=df_missing['alcohol']) plt.title("Outliers of Alcohol") plt.show()
무엇보다 중요한 점은, 결측치나 이상치를 무조건 제거하거나 바꾸기 전에 왜 생겼는지를 먼저 확인하는 것이다.
실측 오류라면 제거하는 것이 맞지만, 의미 있는 값이라면 보존하거나 변환하는 것이 더 적절할 수 있다.
그리고 때로는 결측 그 자체가 데이터 분석에서 중요한 특징이 될 수도 있다.