python으로 회귀 모델 구현하기
해당 포스팅에서는 선형 회귀에는 diamonds, 로지스틱 회귀에는 load_wine 데이터를 사용하여 선형 회귀를 파이썬으로 구현한다.

연속형 vs 범주형 데이터 분리하기
from typing import List
# 범주형 변수 추출 (dtype이 'category'인 열)
categorical_cols: List[str] = list(df.select_dtypes(include='category').columns)
# 연속형 변수 추출 (숫자형 dtype인 열)
continuous_cols: List[str] = list(df.select_dtypes(include=np.number).columns)
데이터 정규화
모델 학습 전 입력 데이터의 스케일 차이를 줄여 수렴 속도와 안정성을 높일 수 있다.
이때 표준화와 브로드캐스팅을 적용할 수 있다.
표준화 (Standard Scaling)
표준화란 평균을 0으로 분산을 1로 각 특성을 변환하는 기법이다.
왜 표준화가 필요할까?
첫째, 스케일 차이에 따른 모델 왜곡 방지 서로 다른 단위와 분포를 가진 특성을 그대로 두면, 일부 특성의 값 범위가 너무 커서 학습 과정에서 다른 특성들이 무시될 수 있다.
표준화를 통해 평균 0, 표준편차 1 분포로 조정하면 모든 특성이 동등한 영향력을 갖게 되어 모델 성능을 안정적으로 끌어올릴 수 있다.
둘째, 경사 하강법 수렴 가속 손실 함수 표면의 곡률이 표준화되지 않은 입력으로 인해 왜곡되면, 경사 하강법이 어느 방향으로 얼마나 이동해야 할지 예측하기 어려워지기 때문이다.
셋째, 이상치 탐지 및 해석 용이 특성별로 Z-점수를 계산하면 평균에서 벗어난 정도를 직관적으로 비교할 수 있어 이상치(outlier)를 식별하기가 쉬워진다.
넷째, 거리 기반 알고리즘 안정화 k-최근접이웃(KNN), k-평균 클러스터링과 같은 거리 기반 알고리즘에서, 특성의 단위나 범위가 다르면 특정 특성이 지나치게 큰 가중치를 갖기 때문이다. 표준화를 적용하면 모든 특성 거리가 동일 스케일로 계산되어 알고리즘의 공정성과 신뢰성을 높일 수 있다.
브로드캐스팅 (Broadcasting)
브로드캐스팅이란 배열 연산 시 차원을 자동 확장하여 계산하는 방식이다.
서로 다른 모양(matrix와 벡터 등)의 배열 간 연산을 자동 확장해 수행할 수 있다.
선형 회귀식의 파라미터 구하기(최적화) - (1)
선형회귀와 같은 회귀 (regression) 모델에서는 평균 제곱 오차(MSE)를 비용함수로 많이 사용한다.
정규 방정식 - 해석적 해
\[J(\boldsymbol{\theta}) = \frac{1}{2m}\sum_{i=1}^m \bigl(\hat y^{(i)} - y^{(i)}\bigr)^2 = \frac{1}{2m}(\mathbf{X}_b\boldsymbol{\theta} - \mathbf{y})^\mathsf{T}(\mathbf{X}_b\boldsymbol{\theta}-\mathbf{y})\]미분이 0이 되는 지점을 찾으면 다음과 같이 해를 구할 수 있다.
\[\frac{\partial J}{\partial \boldsymbol{\theta}} = \frac{1}{m}\,\mathbf{X}_b^\mathsf{T}(\mathbf{X}_b\boldsymbol{\theta} - \mathbf{y}) = 0 \quad\Longrightarrow\quad \mathbf{X}_b^\mathsf{T}\mathbf{X}_b \,\boldsymbol{\theta} = \mathbf{X}_b^\mathsf{T}\mathbf{y}\]하지만 이 방법은 다음과 같은 단점이 존재한다.
- $\mathbf{X}_b^\mathsf{T}\mathbf{X}_b$가 풀랭크(full rank)가 아닐 때 역행렬 존재 불가
- 특성 개수 $n$이 크거나 샘플 수 $m$에 비해 크면 $ O(n^3)$ 복잡도로 느림
- 수치적 불안정성: 조건수(condition number)가 크면 작은 노이즈에도 민감
파이썬으로는 다음과 같이 구현한다.
# 편의를 위해 아까 정리한 X_norm을 다시 pd.DataFrame 형태로 만들기
import pandas as pd
X_df = pd.DataFrame(X_norm, columns=continuous_cols)
# 1. X_norm에서 feature인 X와 예측해야하는 대상인 `price` y를 분리
X: np.ndarray = X_df.drop("price", axis=1).values
y: np.ndarray = X_df["price"].values.reshape(-1, 1)
# 2. 절편항을 추가
m, n = X_norm.shape
X_b = np.c_[np.ones((m, 1)), X] # shape = (m, n+1)
# 3. 요소별로 계산을 진행
# 3-1. 역행렬의 대상인 `X_b^T @ X_b`를 구해 XT_X에 할당해주세요.
XT_X = X_b.T @ X_b # shape = (n+1, n+1)
# 3-2. 역행렬과 곱해지는 `X_b^T @ y`를 구해 XT_y에 할당
XT_y = X_b.T @ y # shape = (n+1, 1)
# 4. 해를 구하기
theta = np.linalg.inv(XT_X) @ XT_y # shape = (n+1, 1)
여기서 @ 연산자는 행렬 곱(matrix multiplication) 연산자이다.
파이썬에서 @는 NumPy 배열이나 행렬 간의 내적(dot product) 또는 행렬 곱셈을 수행할 때 사용한다.
최소 제곱법
잔차 제곱합을 최소화하는 최적화 원리이다.
특이값 분해(SVD)를 이용하여 의사역행렬(pseudoinverse)을 계산한다.
의사역행렬 $X_b^+$를 통해 최소제곱 해를 구한다.(기존 정규방정식의 $\bigl(X_b^\mathsf{T} X_b\bigr)^{-1} X_b^\mathsf{T}$를 대체)
\[\theta = X_b^+\,y\]theta_lstsq = np.linalg.lstsq(X_b, y, rcond=None)[0]
특이값 분해 (SVD)
SVD(특이값 분해, Singular Value Decomposition)는 임의의 행렬 $A\in\mathbb{R}^{m\times n}$를
\[A = U\,\Sigma\,V^\mathsf{T}\]으로 분해하는 기법이다.
- $U\in\mathbb{R}^{m\times r}$와 $V\in\mathbb{R}^{n\times r}$는 직교 행렬 (orthogonal)
- $\Sigma\in\mathbb{R}^{r\times r}$는 특이값을 대각으로 가진 대각 행렬이며 $r=\mathrm{rank}(A)$
SVD를 이용하면 최소제곱 해를 닫힌 형식으로 구할 수 있다. pseudoinverse $\Sigma^+$를 정의하면
\[\Sigma^+_{ii} = \frac{1}{\Sigma_{ii}}\quad(\Sigma_{ii}>0)\]이고, 이때
\[x^* = A^+ b = V\,\Sigma^+\,U^\mathsf{T} b\]로 최소제곱 해 $\min_x|Ax - b|_2^2$를 얻게 된다.
# 1. SVD를 수행하여 U, S, V^T를 구하기
U, S, Vt = np.linalg.svd(X_b, full_matrices=False)
# 2. 위에서 설명한 수식을 참고하여 Pseudo-inverse S_plus를 구하기
S_plus = np.diag(1 / S)
# 3. 앞서 배운 수식을 참고하여 `theta_svd`를 구하기
theta_svd = Vt.T @ S_plus @ U.T @ y
경사 하강법
선형대수 기반의 닫힌 형식 해법(정규방정식, SVD 등)은 $X_b^\mathsf{T}X_b$의 역행렬 계산 또는 전체 행렬 분해가 필요하다.
또한, 특성 수($n$)나 데이터 수 ($m$)가 커지면 메모리와 연산량이 급격히 증가한다는 단점이 있다.
모델 예측 $\hat y = X_b\,\theta$와 실제 $y$ 사이의 평균 제곱 오차는 다음과 같다. \(\mathrm{J(\theta)} = \frac{1}{m}\sum_{i=1}^{m}\bigl(\hat y_i - y_i\bigr)^2\)
학습 반복마다 MSE를 계산해 loss_history에 저장하면
- 수렴 과정을 시각화
- 학습률 스케줄링 또는 조기 종료(early stopping) 기준
로 활용할 수 있다.
선형 회귀 MSE의 파라미터 $\theta$에 대한 그래디언트는 다음과 같다.
\[\nabla_\theta = \frac{2}{m}\,X_b^\mathsf{T}\bigl(X_b\,\theta - y\bigr)\]학습률 $\alpha$를 사용한 업데이트 식은 아래와 같다.
\[\theta \leftarrow \theta - \alpha\,\nabla_\theta\]기울기가 가리키는 손실 상승 방향의 반대로 이동하면서 손실을 점진적으로 줄여 나간다.
from tqdm import tqdm
import numpy as np
import matplotlib.pyplot as plt
# 1. 초기파라미터 설정
theta = np.zeros(X_b.shape[1])
alpha = 0.01
iterations = 1000
loss_history = []
# 정해진 iterations 수만큼 루프를 만들기
for i in tqdm(range(iterations)):
# 현재 매개변수 `theta`에 의한 예측값 `y_pred`를 계산
y_pred = X_b @ theta
# 예측해야하는 실제값 `y`와의 차 `error`를 계산하고,
# `error`를 기반으로 `mse`를 계산
error = y_pred - y.flatten()
mse = np.mean(error ** 2)
loss_history.append(mse)
# 위에서 공부한 식을 토대로 `gradient`를 계산
gradient = (2 / len(y)) * (X_b.T @ error)
# 얻어낸 `gradient`를 기반으로 `theta`를 업데이트해주세요.
theta = theta - alpha * gradient
실제로는 실무에서는 직접 경사 하강법 코드를 매번 작성하기보다, scikit-learn, TensorFlow, PyTorch 같은 라이브러리의 최적화 함수를 사용한다.
기초 개념을 복습하는 정도로 보면 좋을 듯 하다.
sklearn을 통해 로지스틱 회귀 구현 - (2)
이번에는 데이터를 train , test로 나눠서
sklearn 라이브러리를 통해 회귀를 구현해보자.
우선 train, test 데이터셋을 나누고 표준화부터 진행한다.
# 1. Train/test 데이터를 나누기
# test data는 전체 데이터 중 30%를 차지하게 하기
# `train_test_split`은 기본적으로 난수를 사용하기 때문에 함수를 호출할 때마다 다른 결과가 나와서 random_state로 고정하는 것이 좋음
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 2. 표준화를 진행
# `sklearn.preprocessing.StandardScaler`를 사용
# X_train과 X_test를 표준화한 X_train_norm과 X_test_norm을 만들기
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_norm = scaler.fit_transform(X_train)
X_test_norm = scaler.transform(X_test)
모델 훈련 & 검증
# 1. 모델을 선언해서 `clf`에 할당
from sklearn.linear_model import LogisticRegression
# Increase max_iter to address ConvergenceWarning
clf = LogisticRegression(max_iter=1000)
# 2. `.fit`을 통해 모델을 학습
# `ConvergenceWarning`이 떴을 때는 아래의 링크 참고
# https://www.slingacademy.com/article/understanding-scikit-learns-convergencewarning-and-how-to-resolve-it/
clf.fit(X_train_norm, y_train)
# 3. `X_test`를 예측해서 `y_pred`에 할당
y_pred = clf.predict(X_test_norm)
# 4. 이진분류 과제를 여러 가지 평가지표로 평가
# https://scikit-learn.org/stable/modules/model_evaluation.html#classification-metrics
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
# 아래는 ROC-AUC를 그리기
# 참고: https://m.blog.naver.com/koys007/222540017715
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt
# 양성(1) 클래스의 "점수" 얻기: 가능하면 확률, 없으면 decision_function 점수
y_score = clf.predict_proba(X_test_norm)[:, 1]
# FPR, TPR, 임계값과 AUC 계산
fpr, tpr, thresholds = roc_curve(y_test, y_score)
auc = roc_auc_score(y_test, y_score)
# ROC 곡선 시각화 (matplotlib 사용)
plt.plot(fpr, tpr, label=f'ROC-AUC = {auc:.3f}')
plt.plot([0, 1], [0, 1], linestyle='--', label='Random')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
plt.show()
교차 검증 (Cross-Validation)
교차검증(Cross-Validation)은 모델의 성능을 더 신뢰성 있게 평가하기 위해 데이터를 여러 번 나누어 학습과 검증을 반복하는 방법이다.
단순히 한 번의 train/test 분할만으로 성능을 측정하면, 우연히 데이터가 편향되어 들어가서 평가 결과가 과대 또는 과소 추정될 수 있다.
교차 검증은은 데이터를 여러 개의 폴드(fold)로 나눈 뒤, 각 폴드가 한 번씩 검증 데이터가 되도록 순환하며 학습과 평가를 진행한다.
from sklearn.model_selection import cross_val_score
# 5-fold 교차검증 진행
# 각 fold마다 모델을 새로 학습(fit) 후 검증 데이터를 평가하며,
# 최종적으로 평균 F1-score를 산출합니다.
f1_scores = cross_val_score(clf, X_train_norm, y_train, cv=5, scoring='f1')
print("Average F1-score (CV):", f1_scores.mean())
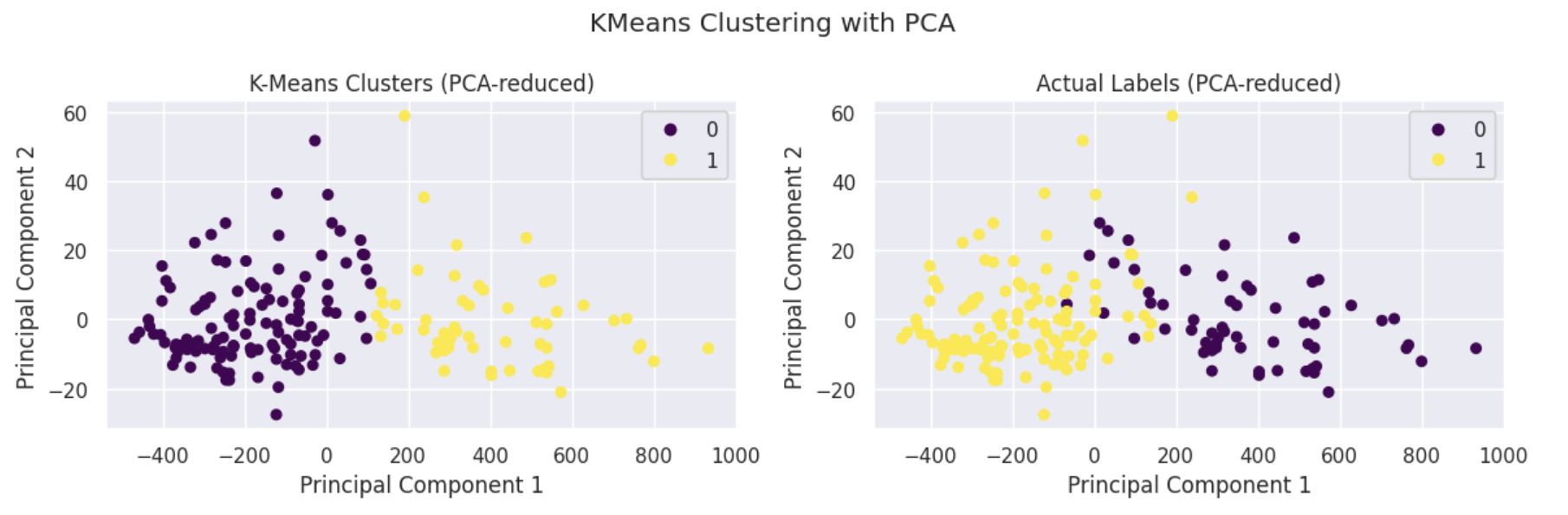
PCA 분석
PCA(주성분 분석)는 데이터의 차원을 줄여서 주요한 패턴을 두세 개의 축으로 표현해 주는 기법이다.
이렇게 하면 고차원 데이터라도 2차원이나 3차원에서 쉽게 시각화할 수 있어, 데이터의 분포나 구조를 직관적으로 파악할 수 있다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca: np.ndarray = pca.fit_transform(X) # (데이터수, 2)
PCA를 적용하고, K-means를 수행해보았다.
#K-Means: PCA로 축소된 데이터 X_pca를 KMeans로 2개의 클래스로 군집화
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=42)
clusters = kmeans.fit_predict(X_pca)