VQA를 위한 모델 비교
VQA를 위한 여러 모델 비교
이번에 VQA 모델 파인튜닝 챌린지를 하면서 여러 모델들 성능 비교를 해봤다.
BLIP, llava, florence .. 등등을 돌려봤는데 생각보다 성능이 너무 안좋거나 GPU가 딸려서 Qwen이 가장 나아 보였다.
처음에 BLIP 논문에 자기 모델 성능 좋길래 삽질했는데 성능이 너무 안좋아서 뭐지 싶었는데 얘네 뻥 친거아님 ? ㅡㅡ
역시 직접 돌려봐야 앎.
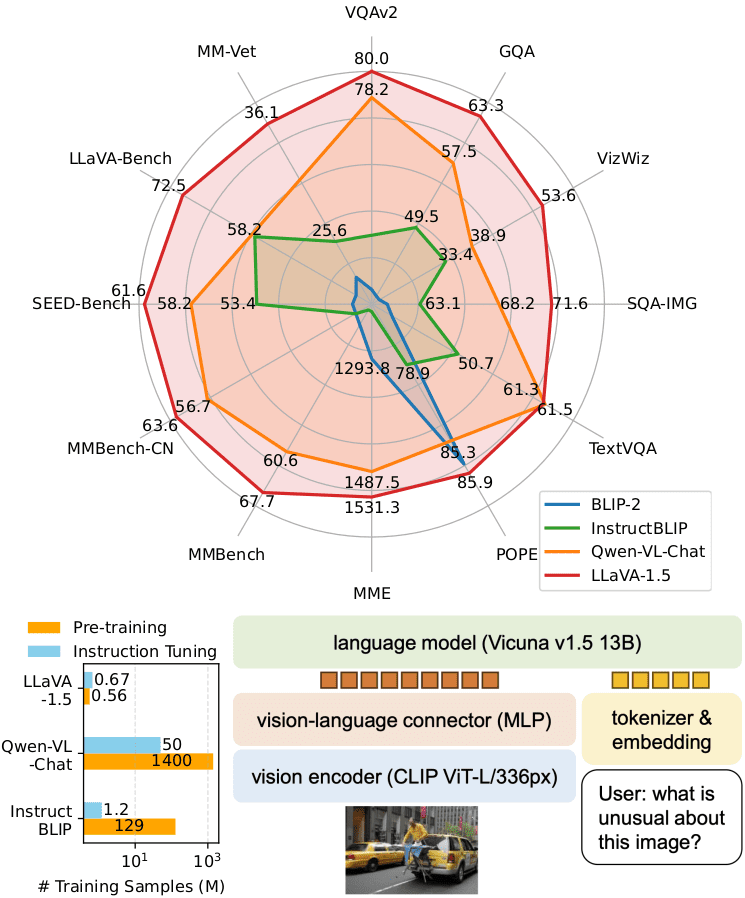
사진은 LLaVA에서 제공하는 시각화 자료긴 한데 확실히 VQA에서는 Qwen이랑 LLaVA가 돌려봤을 때도 성능이 거의 압도적으로 높긴 했다.
둘 중에서는 Qwen이 전반적으로 제일 좋긴 했다. 시간만 많았어도 빨리 깨닫고 Qwen만 팠을 텐데 .. 아쉽
그래서 GPT한테 Qwen 시리즈 비교 좀 해달라고 해봤다. (근데 요즘 GPT가 시위하는지 정리를 잘 못하는 것 같고, 딥리서치도 잘 못하는 것 같음 ..;)
Qwen 모델 목록 및 버전
| 모델명 | 파라미터 수 | 문맥 길이 | 주요 벤치마크 성능 (MMLU 등) | 핵심 특징 | 특화 도메인/용도 | 공개 여부 및 라이선스 |
|---|---|---|---|---|---|---|
| Qwen-7B (1세대) | 약 7B | 최대 32K (초기 공개 시 2K) | MMLU 5-shot 기준 LLaMA2-13B 수준 이상 (동급 13B 모델도 능가) | LLaMA 기반 Transformer 구조. 2.2조 토큰 규모 다국어 데이터(중∙영 중점) 사전학습. 코드, 수리 추론 등 다양한 과제에서 동급 최고 성능. 도구 활용 및 에이전트 기능 지원 | 범용 (지식 질의응답, 번역, 코딩 등) | 공개됨 (가중치 배포), Tongyi Qianwen 전용 라이선스 (비상업 용도) |
| Qwen-14B (1세대) | 약 14B | 최대 8K (초기 공개 사양) | MMLU 등 벤치마크에서 Qwen-7B 대비 향상, 일부 항목은 30B급 모델에 필적 | 7B 대비 매개변수 증가로 언어 이해/추론 향상. 약 3.0조 토큰 학습. 다양한 도메인 지식 강화 및 8K 컨텍스트로 긴 입력 처리 개선 | 범용 (고급 언어이해, 추론 등) | 공개됨 (가중치 배포), Tongyi Qianwen 전용 라이선스 (비상업 용도) |
| Qwen-72B (1세대) | 약 72B | 최대 32K | MMLU 등에서 LLaMA2-70B 상회하는 최상위 성능 (예: MMLU ~84%) | 대규모 LLM(72B)으로 3.0조 토큰 학습. 초거대 파라미터로 지식, 추론, 수학 등 종합 성능 최고 수준. 32K 토큰 긴 문맥 지원 및 시스템 프롬프트 최적화 적용 | 범용 (복잡한 문제 해결, 고급 AI 비서) | 공개됨 (가중치 배포), Tongyi Qianwen 전용 라이선스 (※72B는 상업 이용 제한) |
| Qwen1.5-7B | 7.6B (표기상 7B) | 32K | MMLU 61.0%, C-Eval 74.1%, GSM8K 62.5% 등 동급 최고 수준 (LLaMA2-7B 대비 우수) | Qwen 시리즈 1.5세대 (“Qwen2” 베타 버전). 0.5~110B까지 8가지 모델 규모 공개. 대화 적합도 개선(RLHF 튜닝) 및 다국어 성능 향상. 전 모델 문맥길이 32K로 통일 지원 | 범용 (대화형 AI, 다국어 응답) | 공개됨 (가중치 배포), Tongyi Qianwen 전용 라이선스 (비상업) |
| Qwen1.5-14B | 14.3B (표기상 14B) | 32K | MMLU 67.6%, C-Eval 78.7%, GSM8K 70.1% 등 (동급 13~34B 모델 대비 우수) | 중형(14B) 모델로, 1세대 대비 언어 이해·추론 성능 큰 폭 향상. 다국어 및 코드/수학 능력 보강, 대화형 튜닝 개선으로 인간 선호도 준수 | 범용 (고난도 질의응답, 추론 등) | 공개됨 (가중치 배포), Tongyi Qianwen 전용 라이선스 (비상업) |
| Qwen1.5-72B | 72B 이상 (110B MoE 모델도 공개) | 32K | MMLU 77.5%, C-Eval 84.1%, GSM8K 79.5% 등 (LLaMA2-70B 대비 모든 벤치마크 상회) | 초거대 72B 모델로 1세대 대비 전분야 성능 향상. 채팅 모델은 인간 선호도에 더욱 잘 맞춤. 멀티모달 지원 기반 확보 (이미지 이해 모델 별도) | 범용 (연구 및 상용 AI 모델 개발 기준) | 공개됨 (가중치 배포), Tongyi Qianwen 전용 라이선스 (※72B는 연구 목적 공개) |
| Qwen2-7B | 7.0B (표기상 7B) | 128K (YaRN 기술로 확장) | MMLU ~70.3% (Qwen1.5 대비 ≈+9); Math 52.9 → 69.0 향상 | Qwen 2세대. Transformer 성능 개선(SwiGLU, QKV bias, GQA 등). 대용량 7조+ 토큰 학습으로 지식 대폭 증가. 대부분 오픈모델 능가, 일부 폐쇄모델에 필적하는 성능 달성. 문맥 128K까지 확대 지원 (긴 입력 처리 강화) | 범용 (다국어 이해, 생성, 코딩, 수학 등) | 공개됨 (Apache-2.0) |
| Qwen2-72B | 72.7B (표기상 72B) | 128K (긴 문맥 지원) | MMLU ~84.2%, MATH 69.0, 코드 등 최고 성능. Qwen1.5-72B보다 지식·추론 향상 | 거대 모델(72B)로 지식응답, 추론, 코딩 등 전영역에서 당시 최상위 성능. Qwen2.5 출시 전까지 Alibaba 공개모델 중 최고 성능. (Qwen2에 MoE 57B→14B 활성 모델도 도입) | 범용 (고난이도 문제 해결, 전문 도메인 질의) | 공개됨 (Apache-2.0) 상업 사용 가능 |
| Qwen2.5-7B | 7.61B (표기상 7B) | 128K 입력 / 최대 8K 출력 | MMLU 74.2% (→Qwen2-7B 대비 +3.9); MATH 75.5 (↑+22.6); MultiPL-E 75.1 등 | Qwen 2.5세대. 학습 데이터 18조 토큰으로 확대해 지식량 증대. 중간 규모(3B·14B·32B) 모델 추가 공개. 코딩(Qwen2.5-Coder 활용)과 수학 능력 비약적 향상. 인간 선호도(Arena 등) 크게 개선. 대부분 Apache-2.0 오픈소스 전환 | 범용 (경량 애플리케이션부터 중규모 서비스까지) | 공개됨 (Apache-2.0) |
| Qwen2.5-72B | 72.7B (표기상 72B) | 128K 입력 / 최대 8K 출력 | MMLU 86.1% (→Qwen2-72B +1.9); MATH 83.1 (↑+14.1); Arena-Hard 승률 81.2% (↑+33) 등 | 당시 공개 최강 성능 72B 모델. 지식, 논리, 코딩 모두 GPT-4 수준에 근접. 구조적으로는 Dense 모델 (MoE 미사용)이며 128K 긴 문맥 처리 안정화. 다만 상업용으론 제한됨 | 범용 (최고 성능 요구되는 연구 및 산업) | 공개됨 (가중치 배포) 그러나 제한적 라이선스: Qwen License (상업 활용 제한) |
| Qwen2.5-Max | 235B 총매개변수 (MoE, 활성 약 22B) | 32K+ (추론 API 상 지원) | Arena-Hard 등 챗봇평가 7위 (GPT-4o 등과 대등); LiveCodeBench 등 코딩 평가 SOTA 달성 | 초대규모 MoE 모델 (전문가혼합 방식). 20조+ 토큰 사전학습 후 SFT/RLHF로 정밀 보강. 지식, 상식, 코딩, 추론 등 전분야 SOTA 성능. 오픈모델 DeepSeek V3 능가 및 GPT-4 대안으로 개발됨 | 범용+고급 (초거대 챗봇, 복잡한 멀티스텝 추론, 코딩 비서 등) | 미공개 (가중치 비공개, Alibaba Cloud API 통해 제공) |
| Qwen2.5-Coder (7B 등) | 7.61B (7B) 등 ※1.5B~32B 시리즈 |
128K | HumanEval 74.7%, MBPP 85.6 등 코드 분야 SOTA; MMLU 68.7% (일반지식 유지) | 코드 특화 LLM. 5.5조 토큰 코드 및 텍스트로 추가 학습하여 다중 언어 코딩 능력 향상. 92개 프로그래밍 언어 지원 및 FIM(fill-in-middle) 기능. 수학·일반 상식도 기반 모델 수준 유지. 7B 모델이 20B+ 코드모델 능가하는 성과 달성 | 프로그래밍 특화 (코드 생성, 디버깅, 다중언어 지원) | 공개됨 (가중치 배포, 0.5/1.5/7/14/32B) Apache-2.0 라이선스 |
| Qwen3-32B (3세대 Dense) | 32.5B (표기상 32B) | 128K | MMLU 약 86% 추정 (Qwen2.5-72B와 대등); 코드/추론 등은 이전세대 72B 능가 | Qwen 3세대 Dense 플래그십. 하이브리드 사고 모드 도입 – 빠른 응답/깊은 사고 2모드 지원. 119개 언어 지원하는 광범위 다국어 능력. 약 36조 토큰 프리트레인(이전 대비 2배)으로 지식 대폭 증가. 효율적 구조개선으로 소규모로 동급 최고 성능 달성 (예: 32B 모델이 전세대 72B 수준 성능) | 범용 (멀티언어 지능형 비서, 지식 응답, 고차원 추론) | 공개됨 (가중치 배포, 0.6/1.7/4/8/14/32B Dense) Apache-2.0 라이선스 |
| Qwen3-235B-A22B (3세대 MoE) | 235B (MoE, 활성 22B) | 128K | 다양한 평가에서 GPT-4급 준하는 최고 성능 (예: 작은 4B 모델로도 Qwen2.5-72B 능가) | 혼합전문가(MoE) 구조 적용 – 128개 전문가 중 8개 활성화. 총 2350억 매개변수 중 10%만 토큰별 활성으로 효율적 추론. DeepSeek 등 타 MoE 대비 우수한 지식, 추론, 코딩 성능 입증. Qwen3 시리즈의 RLHF/추론 모드 결합 포스트트레이닝 모델 공개 | 범용 (초거대 지능형 에이전트, 복잡한 문제 해결) | 공개됨 (가중치 배포, 30B-A3B 및 235B-A22B MoE) Apache-2.0 라이선스 |
| Qwen3-Max | – (비공개, Qwen3 계열 최상위) | 128K+ (컨텍스트 캐시 지원) | 에이전트 활용 및 도구 사용 등 특화 작업 SOTA (최신 프리뷰 대비 성능 향상) | Alibaba 상용 최고 성능 LLM (2025). Qwen3 기반 강화판으로, 에이전트 프로그래밍/툴 호출 능력 특별 향상. 복잡한 다단계 작업에 최적화된 모델로 출시. (DeepSeek-R1 등 ‘심층 사고’ 모델들과 경쟁) | 고급 에이전트용 (툴 사용, 계획 수립, 복합적 질의응답) | 미공개 (Alibaba Cloud API 서비스 – Qwen3-Max 엔드포인트 제공) |