지식 관계를 활용한 GraphRAG
영어 원문 보러가기 Microsoft GraphRAG 논문 리뷰
해당 포스팅은 위의 링크 포스팅을 참고하여 정리하였다.
등장 배경
최근 RAG 기술이 LLM의 hallucination 현상을 줄이는 유용한 기술로 꾸준히 거론되고 있다. Baseline RAG는 일반적으로 벡터 데이터베이스와 LLM을 통합한다.
벡터 데이터베이스는 사용자 질의에 대한 맥락 정보를 저장하고 검색하며, LLM은 검색된 맥락을 기반으로 답변을 생성한다.
이러한 접근 방식은 많은 경우에 효과적이지만,
multi-hop 추론이나 서로 다른 정보를 연결해야 하는 질문에 답변할 때는 어려움을 겪는다.
예를 들어, “반역자 알렉투스를 물리친 사람의 아들의 이름은 무엇인가?” 라는 질문의 답을 생각해보자.
Baseline RAG는 다음과 같은 단계로 이 질문에 답한다.
- 알렉투스를 물리친 사람이 누구인지 찾기
- 1번에서 찾은 사람의 아들을 조사하기 (가족 정보)
- 2번에서 찾은 아들의 이름 알아보기
하지만 1번 단계에서 Baseline RAG는 의미적 유사성을 기반으로 텍스트를 검색하기 때문에,
데이터세트에 특정 세부 정보가 명시적으로 언급되지 않은 복잡한 질의에는 직접 답변하지 않아 문제가 발생한다.
이러한 한계로 인해 필요한 정확한 정보를 찾기가 어려워지고,
빈번한 질의에 대한 Q&A 쌍을 수동으로 생성하는 것과 같이 비용이 많이 들고 비실용적인 솔루션이 필요한 경우가 많다.
이러한 과제를 해결하기 위해 Microsoft Research는 지식 그래프를 통해 RAG 검색 및 생성을 강화하는 새로운 방법인 GraphRAG를 도입했다. Microsoft GraphRAG Github 보러가기 Microsoft GraphRAG 논문 보러가기
GraphRAG란?
의미적으로 유사한 텍스트를 검색하기 위해 벡터 데이터베이스를 사용하는 기본 RAG와 달리,
GraphRAG는 지식 그래프(KG)를 통합하여 RAG를 향상시킨다.
GraphRAG의 파이프라인
그래프래그의 파이프라인은 일반적으로 (1) 인덱싱 (2) 쿼리 라는 두가지 기본 프로세스로 구성된다.
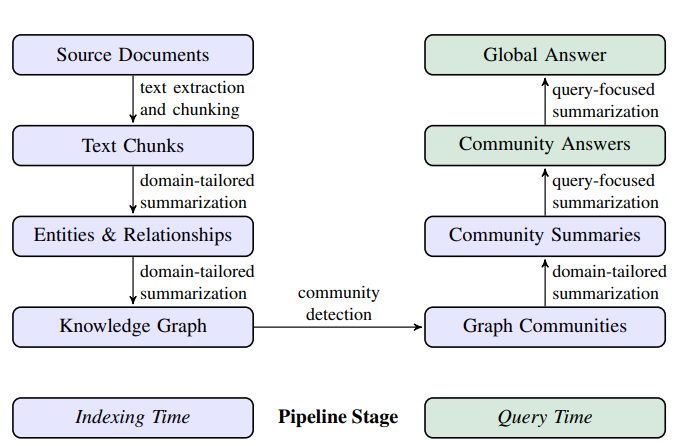
-
Indexing Time
-
Query Time