LoRA를 이용한 Adaptor 모듈 추가 학습
대형 모델(LLM, VLM)은 파라미터 수가 수십억~수천억 개에 달해 전체 파라미터를 학습하기엔 비용이 과도하다.
이를 해결하기 위해 등장한 접근이 PEFT (Parameter-Efficient Fine-Tuning) 기법이며, 그 중 대표적인 방식이 LoRA (Low-Rank Adaptation) 와 Adapter 구조다.
이번 포스팅에서는 Adaptor 모듈을 LoRA로 추가 학습하는 구조와 원리를 정리한다.
LoRA란?
- 기존 모델 파라미터를 고정한 채, 저랭크 행렬(LoRA 레이어)만 학습한다.
-
모델의 큰 weight matrix 𝑊를 다음과 같이 분해한다.
\[W' = W + \Delta W = W + BA\]학습 중에는 𝐴,𝐵만 업데이트되며, 기존 𝑊는 freeze되어 메모리와 연산량이 대폭 감소한다.
Adapter란?
-
Adapter는 기존 모델 레이어 사이에 작은 모듈(MLP 유사 구조)을 삽입하는 방식이다. Activation을 변경하기 위함이다
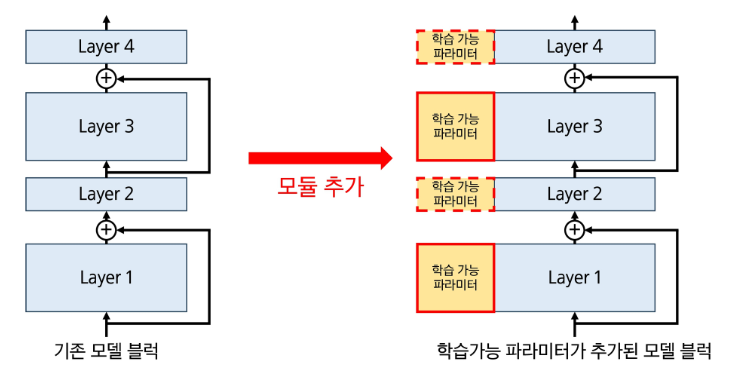
-
기존 모델을 수정하지 않고도 태스크 특화 적응이 가능하다.
[Input] ↓ Transformer Layer ↓ Adapter Layer (Down → Nonlinearity → Up) ↓ [Output]- 일반적인 구성
- Down projection: 입력 차원 축소 (예: 4096 → 64)
- Non-linear activation (ReLU, GELU 등)
- Up projection: 다시 원래 차원으로 복원 (64 → 4096)
- 일반적인 구성
LoRA + Adapter 결합 구조
-
LoRA와 Adapter는 모두 PEFT 계열이며, 결합 시 다음 두 가지 방식이 있다.
방식 설명 장점 LoRA-injected Adapter Adapter 내부의 FC layer에 LoRA 모듈 삽입 Adapter 파라미터 효율 향상 Parallel LoRA + Adapter LoRA와 Adapter를 병렬로 연결하여 합산 태스크 적응 유연성 향상 -
즉, LoRA는 weight update 효율을, Adapter는 task-specific 표현력을 담당한다.
Hugging Face peft 적용 예시
- Hugging Face의
peft라이브러리를 사용하면, 기존 모델에 쉽게 LoRA + Adapter 모듈을 추가할 수 있다.from transformers import AutoModelForCausalLM, AutoTokenizer from peft import LoraConfig, get_peft_model # 1. 기본 모델 로드 model_name = "meta-llama/Llama-2-7b-hf" model = AutoModelForCausalLM.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) # 2. LoRA 설정 lora_config = LoraConfig( r=8, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM", ) # 3. LoRA 모듈 삽입 model = get_peft_model(model, lora_config) model.print_trainable_parameters() - 파라미터
r(랭크)- LoRA에서 추가되는 두 행렬 𝐴 ∈ 𝑅(𝑟×𝑑), 𝐵 ∈ 𝑅(𝑑×𝑟)의 차원을 결정함. 즉, 얼마나 작은 rank로 weight를 근사할지를 정함. 작을수록 효율적이지만 표현력은 떨어짐. 보통 4~16 사이로 설정.
lora_alpha(Scaling factor)- LoRA에서 학습된 업데이트 𝐵𝐴를 얼마나 강하게 반영할지를 조절하는 스케일 계수. 수식상으로는 최종 weight가 다음과 같이 적용됨
- 즉, alpha 값이 클수록 LoRA 업데이트의 영향이 커짐
target_modules- LoRA를 삽입할 layer 이름을 지정함. 예를 들어 Transformer 구조에서는 보통 [“q_proj”, “v_proj”] (Attention의 Query, Value projection 부분)에 적용함. BERT나 LLaMA 등 모델마다 target 이름이 다를 수 있음.
lora_dropout(드롭아웃 비율)- LoRA 레이어에 적용되는 dropout 확률. 작은 데이터셋이나 overfitting 가능성이 있을 때 regularization 효과를 위해 사용함. 일반적으로 0.05~0.1 사이
bias- LoRA 적용 시 bias 파라미터를 학습할지 여부.
task_type- LoRA 적용 모델의 구조 지정
- 예시
"CAUSAL_LM"→ GPT, LLaMA 계열 (텍스트 생성)"SEQ_CLS"→ 문장 분류"TOKEN_CLS"→ 토큰 단위 태깅"SEQ_2_SEQ_LM"→ T5, BART 등 인코더-디코더 구조
LoRA만으로 충분하지 않은 경우, Adapter 레이어를 별도로 추가 가능하다.
from peft import AdaLoraConfig, get_peft_model
ada_config = AdaLoraConfig(
target_r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
task_type="CAUSAL_LM",
)
model = get_peft_model(model, ada_config)
또는 아래와 같이 huggingface의 adapter-transformers 라이브러리를 사용할 수 있다.
from transformers import AutoModelWithHeads
model = AutoModelWithHeads.from_pretrained("bert-base-uncased")
model.add_adapter("classification")
model.train_adapter("classification")
정리
| 항목 | Full Fine-tuning | LoRA | Adapter | LoRA + Adapter |
|---|---|---|---|---|
| 학습 파라미터 | 100% | 약 0.1~1% | 약 1~3% | 약 1~4% |
| 기존 모델 수정 | 없음 | 없음 | 있음 | 있음 |
| 저장 용량 | 매우 큼 | 매우 작음 | 작음 | 중간 |
| 병합 용이성 | - | 가능 | 가능 | 가능 |
| 대표 용도 | 대규모 재학습 | 효율적 튜닝 | 태스크 적응 | 정밀 커스터마이즈 |
LoRA는 효율성을, Adapter는 유연성을 가져온다. 두 방식을 결합하면 대형 모델을 저비용으로 태스크 특화 튜닝할 수 있다.
특히 Multi-modal 모델(VQA, Captioning, Multilingual Chat 등)에서는 LoRA-injected Adapter 구조가 성능과 효율 모두에서 매우 좋은 tool이다.