[논문 리뷰] From Local to Global: A GraphRAG Approach to Query-Focused Summarization
Microsoft의 GraphRAG paper를 리뷰해 보겠다!
1. Abstract & Introduction
- RAG
- Retrieval-augmented generation (RAG)는 외부 지식 소스에서 관련 정보를 검색하여, 대형 언어 모델(LLM)이 프라이빗 또는 이전에 보지 못한 문서 컬렉션에 대해 질문에 답할 수 있도록 돕는다.
기존 RAG의 한계
- Global questions의 한계
- 전통적인 RAG 방식은 로컬화된 정보가 작은 레코드 세트에서 답변을 찾을 수 있는 질문에는 효과적이다.
- 하지만 RAG는 전체 텍스트 데이터셋에 대한 글로벌 질문에는 실패한다.
- 예를 들어, “이 데이터셋의 주요 주제는 무엇인가?”, “지난 10년 동안 학문적 발견에 어떤 트렌드가 있었는지?”와 같은 질문은 쿼리 중심 요약(Query-Focused Summarization, QFS) 작업으로, 단순한 검색 작업이 아니다. 기존의 QFS 방법들은 RAG 시스템에서 index된 대규모 텍스트에는 잘 확장되지 않는다.
GraphRAG의 제안
- 이러한 문제를 해결하기 위해, 우리는 GraphRAG라는 그래프 기반 접근법을 제시한다.
- 이 방법은 사용자 질문의 일반성과 소스 텍스트의 양 모두에 대해 확장 가능하며, 프라이빗 텍스트 데이터셋에서 질문에 답할 수 있도록 돕는다.
-
GraphRAG는 LLM을 사용해 두 단계로 그래프 인덱스를 구축한다.
1) 첫 번째 단계에서는 소스 문서에서 엔티티 지식 그래프를 도출하고,
2) 두 번째 단계에서는 첫 번째 단계에서 도출한 지식그래프가 밀접하게 관련된 엔티티 그룹에 대한 커뮤니티로 분할되고, 이 커뮤니티에 대한 요약을 미리 생성한다.
GraphRAG의 응답 방식
- GraphRAG는 맵-리듀스(Map-Reduce) 방식으로 커뮤니티 요약들을 처리하여 질문에 대한 최종 응답을 생성한다.
- 맵 단계에서는 각 커뮤니티 요약들이 독립적으로 부분적인 응답을 제공하고, 리듀스 단계에서는 이들을 결합하여 최종 글로벌 응답을 생성한다.
- Map-Reduce?
- 데이터를 처리하고 분석하는 분산 컴퓨팅 모델로, 대규모 데이터를 효율적으로 처리할 때 자주 사용되는 방식이다.
- 주로 병렬 처리에서 유용하게 쓰이며, 두 단계(Map, Reduce)로 나누어 진다.
GraphRAG의 성능
- 주어진 질문에 대해, (1)각 커뮤니티 요약을 사용해 부분적인 응답을 생성하고, (2)모든 부분 응답을 결합하여 최종 응답을 생성한다.
- 1백만 토큰 범위의 데이터셋에 대해 글로벌한 의미 추론(global sensemaking) 질문을 처리하는 GraphRAG는 기존의 RAG 시스템에 비해 완전성(comprehensiveness)과 다양성(diversity) 모두에서 현저한 성능 향상을 보였다.
2. Background
1) RAG Approaches and Systems
- RAG(리트리벌-어그멘티드 제너레이션)는 사용자가 제시한 질문에 대해 외부 데이터 소스에서 관련 정보를 검색하여 이를 바탕으로 LLM(또는 다른 생성 AI 모델)에서 답변을 생성하는 방식이다.
-
이때 검색된 정보는 프롬프트 템플릿에 담겨 LLM에 전달되어, LLM은 이를 기반으로 응답을 생성한다.
- 기존의 RAG 접근법
- 전통적인 RAG 시스템에서는 검색 과정에서 질문과 의미상 유사한 레코드를 선택하여, 그 정보를 바탕으로 답변을 생성한다.
- 일반적으로 벡터 RAG는 텍스트 임베딩을 사용하여, 벡터 공간에서 질문에 가장 가까운 레코드를 검색하는 방식을 사용한다. 이때 의미적 유사성이 중요한 역할을 한다.
-
벡터 RAG와 GraphRAG의 차이점
특징 벡터 RAG GraphRAG 주요 목적 로컬화된 정보 기반의 짧은 질문에 최적화 전체 데이터셋에 대한 글로벌한 의미 추론 데이터 처리 방식 검색된 소수의 레코드를 사용해 답변 생성 전체 데이터셋에 대한 글로벌한 요약 생성 적합한 질문 유형 정보가 특정 레코드에 국한된 질문 데이터셋 전체에 대한 전반적인 이해를 요구하는 질문 성능 한계 전체 데이터셋에 대한 글로벌한 이해 부족 데이터셋을 그래프 형태로 처리하여 글로벌한 의미 추론 가능 검색 방식 텍스트 임베딩을 사용하여 의미적으로 유사한 레코드 검색 그래프 인덱스와 커뮤니티 탐지를 사용하여 데이터 파티셔닝 응답 처리 관련 레코드를 기반으로 답변을 생성 커뮤니티 요약을 기반으로 최종 글로벌 응답 생성 장점 효율적이고 빠른 응답 생성 전체 데이터를 종합하여 더 깊고 다양한 답변 제공 - GraphRAG의 발전
- GraphRAG는 기존 RAG 전략들을 발전시킨 방식으로, 데이터의 큰 부분에 대한 요약을 “자기 기억(self-memory)” 형태로 활용하여 이후 질문에 대한 답변을 제공한다.
- 이러한 요약은 병렬로 생성되어 글로벌 요약으로 반복적으로 집합된다.
- 이 과정은 기존의 요약 생성 기법들과 유사하지만, 그래프 인덱스를 사용하고 커뮤니티 탐지를 통해 주제별 데이터 파티셔닝을 생성하는 점에서 차별화된다.
- 기존 요약 기법들과의 차이점
- GraphRAG는 기존의 계층적 인덱싱 방식에서 발전된 기법으로,
- 데이터를 그래프 인덱스 형태로 변환한 후 그래프 기반 커뮤니티 탐지를 통해 데이터셋의 주제별 구분을 수행한다.
- 이 방식은 기존의 방법들과 달리, 데이터를 테마별로 분할하여 요약을 생성한다는 점에서 차별화된다.
2) Using Knowledge Graphs with LLMs and RAG
- KG 추출 방법
- 자연어 텍스트 코퍼스에서 지식 그래프를 추출하는 방법에는 규칙 매칭, 통계적 패턴 인식, 클러스터링, 임베딩 등이 있다.
- 이러한 방법들은 기존 연구에서 널리 사용되었으며, GraphRAG는 LLM을 활용한 지식 그래프 추출에 대한 최신 연구에 속한다.
- 기존의 KG 활용 방법들과의 차이점
- 다른 접근법들은 지식 그래프를 사용하여 검색을 향상시키는 방식을 사용한다. 예를 들어, LLM 기반 에이전트가 질문 시 그래프를 동적으로 탐색하며, 문서 요소(예: 패시지, 표)와 그들 간의 의미적 유사성이나 구조적 관계를 표현한 간선들을 이용한다.
- 반면, GraphRAG는 그래프의 내재된 모듈성에 주목하며, 그래프를 중첩된 모듈 커뮤니티로 나누어 데이터셋을 주제별로 파티셔닝하고, 이를 통해 점점 더 글로벌한 요약을 생성한다.
- GraphRAG의 핵심 아이디어
- GraphRAG는 커뮤니티 계층 구조를 사용하여 점차적으로 글로벌 요약을 생성한다.
- 즉, LLM을 사용해 각 커뮤니티의 요약을 생성하고, 이를 상위 커뮤니티 요약에 포함시켜 최종적으로 전체 데이터셋에 대한 통합적인 요약을 만든다.
3) Adaptive Benchmarking for RAG Evaluation
- 기존 벤치마크 데이터셋
- 오픈 도메인 질문 응답을 위한 많은 벤치마크 데이터셋이 존재한다. 예를 들어, HotPotQA (Yang et al., 2018), MultiHop-RAG (Tang and Yang, 2024), MT-Bench (Zheng et al., 2024) 등
- 그러나 이러한 벤치마크는 벡터 RAG 성능에 초점을 맞추고 있으며, 명시적인 사실 검색에 대한 성능을 평가한다.
- Adaptive Benchmarking
- 특정 도메인이나 사용 사례에 맞게 평가 벤치마크를 동적으로 생성하는 과정이다.
- 최근 연구에서는 LLM을 활용하여 벤치마크의 관련성, 다양성, 목표 애플리케이션이나 작업과의 일치성을 보장하는 방법이 사용되고 있다.
- LLM 기반 페르소나 생성
- 본 논문에서는 Adaptive Benchmarking 방법을 사용하여 글로벌 의미 추론 질문을 생성한다.
- 이 방법은 LLM을 활용한 페르소나 생성에 기반하며, LLM을 사용하여 다양하고 실제적인 페르소나를 생성하고, 각 페르소나에 맞는 질문을 도출한다.
- 이는 실제 RAG 시스템 사용에 적합한 질문을 만들기 위한 방식으로, 사용자와 그들의 사용 사례를 추론하여 코퍼스별 의미 추론 질문을 생성한다.
4) RAG Evaluation Criteria
- LLM을 이용한 평가
- LLM-as-a-judge 방식
- LLM을 활용해 두 개의 경쟁 모델에서 생성된 답변을 비교하도록 유도함으로써 상대적인 성능을 평가할 수 있다.
- LLM-as-a-judge 방식
- 글로벌 의미 추론 질문에 대한 평가 기준
- 본 논문에서는 글로벌 의미 추론 질문에 대해 RAG 시스템이 생성한 답변을 평가하기 위한 새로운 기준을 설계했다.
Methods
GraphRAG workflow
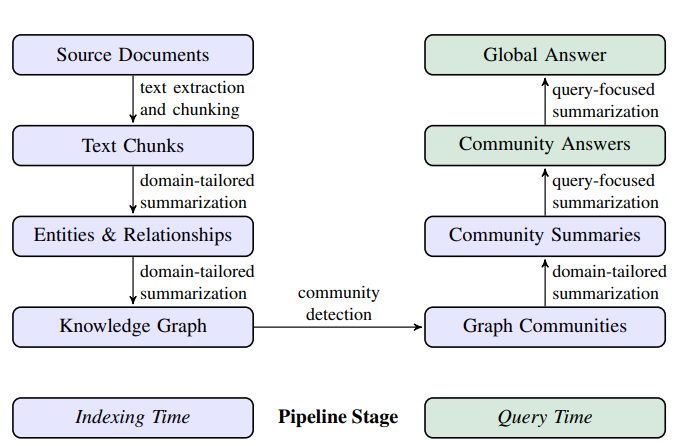
1) Source Documents → Text Chunks
- text chunks로 문서들을 나누고, 이 chunk로부터 LLM이 정보를 추출할 수 있도록 한다.
- text chunks 크기 설정도 중요한 옵션이다
- 긴 텍스트 : LLM 호출 횟수를 줄여 비용 절감 가능. But, 덩어리 앞부분에 나오는 정보는 recall이 떨어질 수 있다.
2) Text Chunks → Entities & Relationships
- 엔티티 및 관계 추출
- 이 단계에서는 LLM이 각 text chunks에서 중요한 엔티티와 엔티티 간 관계를 추출하도록 한다.
- text chunks에 대한 프롬프트는 도메인에 맞는 few-shot 예시를 사용하여 인-컨텍스트 학습을 통해 조정할 수 있다.
- 주장 추출 (Claim Extraction)
- LLM은 추출된 엔티티에 대해 주장(claims)을 추출할 수 있다. 주장은 중요한 사실적 진술로, 예를 들어 날짜, 사건, 다른 엔티티와의 상호작용 등을 포함한다.
- ex)
NeoChip의 주식은 NewTech Exchange에서 첫 거래 주간 동안 급등했다.
3) Entities & Relationships → Knowledge Graph
- LLM을 통해 entity, relationship, claim을 추출하는 과정
- 추상적 요약(abstractive summarization)의 형태로, 텍스트에 명시적으로 언급되지 않은 개념들에 대한 의미 있는 요약을 생성한다
- 지식 그래프 생성
- 추출된 엔티티와 관계는 그래프의 노드와 간선으로 변환된다.
- 각 노드와 간선에 대한 설명은 집합적으로 요약된다.
- 특히 관계는 중복된 관계를 기반으로 가중치를 부여한 간선으로 집합된다. claim은 비슷한 방식으로 집합적으로 처리된다.
4) Knowledge Graph → Graph Communities
- Graph Community 탐지
- 이전 단계에서 생성된 그래프 인덱스를 기반으로, 그래프를 강하게 연결된 노드들의 커뮤니티로 나눈다.
- 커뮤니티 탐지 기법은 데이터셋의 구조적 특징을 바탕으로 노드를 그룹화하는 데 사용된다. ex) Leiden 알고리즘
- Leiden 커뮤니티 탐지
- 이 알고리즘은 각 커뮤니티 안에서 하위 커뮤니티를 재귀적으로 탐지하여, 더 이상 분할할 수 없는 단말 커뮤니티(leaf communities)에 도달할 때까지 계속해서 커뮤니티를 세분화한다.
5) Graph Communities → Community Summaries
- 커뮤니티 요약 생성
- 커뮤니티 계층에서 각 커뮤니티에 대한 보고서 형식의 요약을 생성한다.
- 커뮤니티 요약 생성 방법
- Leaf-level communities
- element 요약은 우선순위를 두어 처리된다.
- LLM의 컨텍스트 윈도우에 반복적으로 추가된다.
- 이때 우선순위는 커뮤니티 간선의 출발 노드와 도착 노드의 결합된 차수(즉, 전체적인 중요도)에 따라 결정된다.
- 각 간선에 대해 출발 노드, 도착 노드, 간선 자체, 그리고 관련 주장에 대한 설명이 추가된다.
- Higher-level communities
- 모든 element 요약이 컨텍스트 윈도우의 토큰 제한 내에 들어가면, 단말 커뮤니티와 마찬가지로 모든 요소 요약을 요약한다.
- 그렇지 않으면, 하위 커뮤니티를 요소 요약의 길이 순서대로 랭킹을 매기고, 하위 커뮤니티 요약(짧은 요약)을 해당 요소 요약(긴 요약)으로 대체하여 토큰 제한 내에 맞출 때까지 반복한다.
- Leaf-level communities
6) Community Summaries → Community Answers → Global Answer
- 이전 단계에서 생성된 커뮤니티 요약을 사용하여, 주어진 사용자 질문에 대한 최종 답변을 다단계 과정으로 생성한다.
- 커뮤니티 구조의 계층적 특성 덕분에, 질문에 대한 답변을 다양한 커뮤니티 수준의 요약을 사용하여 생성할 수 있다.
- 여기서 중요한 점은 어떤 커뮤니티 수준이 요약의 세부사항과 범위에서 가장 적합한 균형을 제공할지 결정하는 것이다.
- global answer 생성 과정
- Prepare community summaries
- 커뮤니티 요약은 무작위로 섞이고 미리 정해진 토큰 크기로 덩어리로 나뉜다.
- 이렇게 하면 관련 정보가 하나의 컨텍스트 윈도우에 집중되는 것이 아니라 여러 덩어리로 분배되어, 중요한 정보가 손실되지 않도록 한다.
- Map community answers
- 중간 답변들은 병렬로 생성된다.
- 또한, LLM은 생성된 답변이 질문에 얼마나 도움이 되는지에 대한 점수를 0에서 100 사이로 매기도록 요청된다.
- 점수가 0인 답변은 필터링된다.
- Reduce to global answer
- 답변들은 새로운 컨텍스트 윈도우에 반복적으로 추가되어 토큰 한도에 맞을 때까지 계속해서 결합된다.
- 이 과정이 끝나면 최종 글로벌 답변이 생성된다.
- Prepare community summaries
Global Sensemaking Question Generation
- RAG 시스템의 평가
- RAG 시스템이 글로벌 의미 추론(global sensemaking) 작업에서 얼마나 효과적인지 평가하기 위해, LLM을 사용하여 코퍼스별 고수준 질문을 생성한다.
- 이 질문들은 특정한 저수준의 사실을 검색하지 않고도 주어진 데이터셋에 대한 전반적인 이해를 평가할 수 있도록 설계된다.
- 질문 생성 알고리즘

- Criteria for Evaluating Global Sensemaking
- head-to-head comparison approach using an LLM evaluator that judges relative performance according to specific criteria
- 평가 기준
- Comprehensiveness (완전성): 답변이 질문에 대한 모든 측면과 세부 사항을 얼마나 잘 포괄하는지 평가한다.
- Diversity (다양성): 답변이 다양한 관점과 통찰을 제공하는 정도를 평가한다.
- Empowerment (강화): 답변이 독자가 주제를 이해하고 정보에 기반한 판단을 내리도록 돕는 정도를 평가한다.
- Directness (직접성) : 추가적으로, 우리는 “직접성”(Directness)이라는 통제 기준을 사용하여, “답변이 질문을 얼마나 구체적이고 명확하게 다루고 있는지”를 평가한다.
- 직접성 <—-> 완전성
3. Analysis
Experiment 1
-
Datasets
데이터셋 설명 토큰 수 텍스트 덩어리 크기 덩어리 중복 크기 Podcast Transcripts Behind the Tech with Kevin Scott 팟캐스트의 공개 대본. Microsoft CTO Kevin Scott과 다양한 과학 및 기술 분야의 사상가들 간의 대화 내용. 약 100만 토큰 1669 × 600 토큰 100 토큰 중복 News Articles 2013년 9월부터 2023년 12월까지의 뉴스 기사 데이터셋. 엔터테인먼트, 비즈니스, 스포츠, 기술, 건강, 과학 등 다양한 범주 포함. 약 170만 토큰 3197 × 600 토큰 100 토큰 중복 - Conditions
-
6가지 조건을 비교
조건 설명 C0 루트 레벨 커뮤니티 요약(가장 적은 수)의 커뮤니티 요약을 사용하여 사용자 질문에 답변 C1 고수준 커뮤니티 요약을 사용하여 질문에 답변. C0의 하위 커뮤니티가 있으면 사용, 없으면 C0 커뮤니티를 내려서 사용 C2 중간 수준 커뮤니티 요약을 사용하여 질문에 답변. C1의 하위 커뮤니티가 있으면 사용, 없으면 C1 커뮤니티를 내려서 사용 C3 저수준 커뮤니티 요약(가장 많은 수)의 커뮤니티 요약을 사용하여 질문에 답변. C2의 하위 커뮤니티가 있으면 사용, 없으면 C2 커뮤니티를 내려서 사용 TS 맵-리듀스 요약 방법을 사용하되, 커뮤니티 요약 대신 소스 텍스트를 섞고 덩어리로 나누어 처리 SS 벡터 RAG 방식으로 텍스트 덩어리를 검색하여 컨텍스트 윈도우에 추가, 토큰 한도가 도달할 때까지 계속 추가 - 조건별 차이점은 컨텍스트 윈도우의 내용이 어떻게 생성되는지에 있다.
- 각 조건에서 사용하는 컨텍스트 윈도우 크기와 답변 생성 프롬프트는 동일하다. (다만, 참조 스타일에 대한 작은 수정이 있을 수 있음.)
- SS가 vector RAG, TS가 맵-리듀스 방식을 사용하는 source text summarization, C0~C3이 GraphRAG 라고 생각하면 됨
-
- Configuration
- LLM: GPT-4-turbo
- Context window: 8k tokens (community summaries, community answers, global answers 모두 동일)
- 그래프 인덱싱: 600-token window
- 하드웨어: VM (16GB RAM, Intel Xeon Platinum 8171M @ 2.60GHz)
- 커뮤니티 탐지 알고리즘: Leiden (graspologic 라이브러리 사용)
- 인덱싱 시간: Podcast 데이터셋 기준 약 281분
- 프롬프트: Appendix E~F 참고 (엔티티·관계 추출, 평가 기준 정의 포함)
Results 1
- Global approaches vs. vector RAG
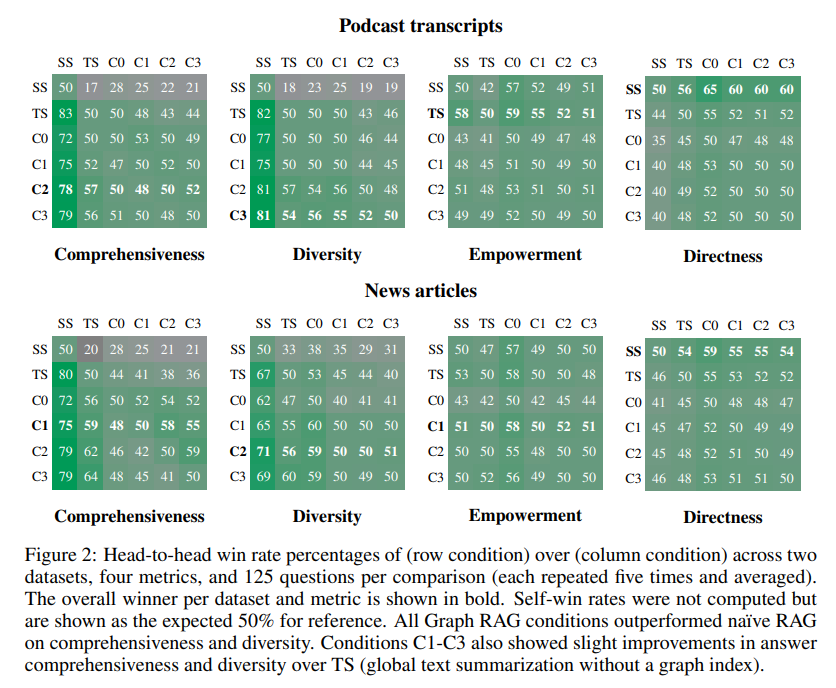
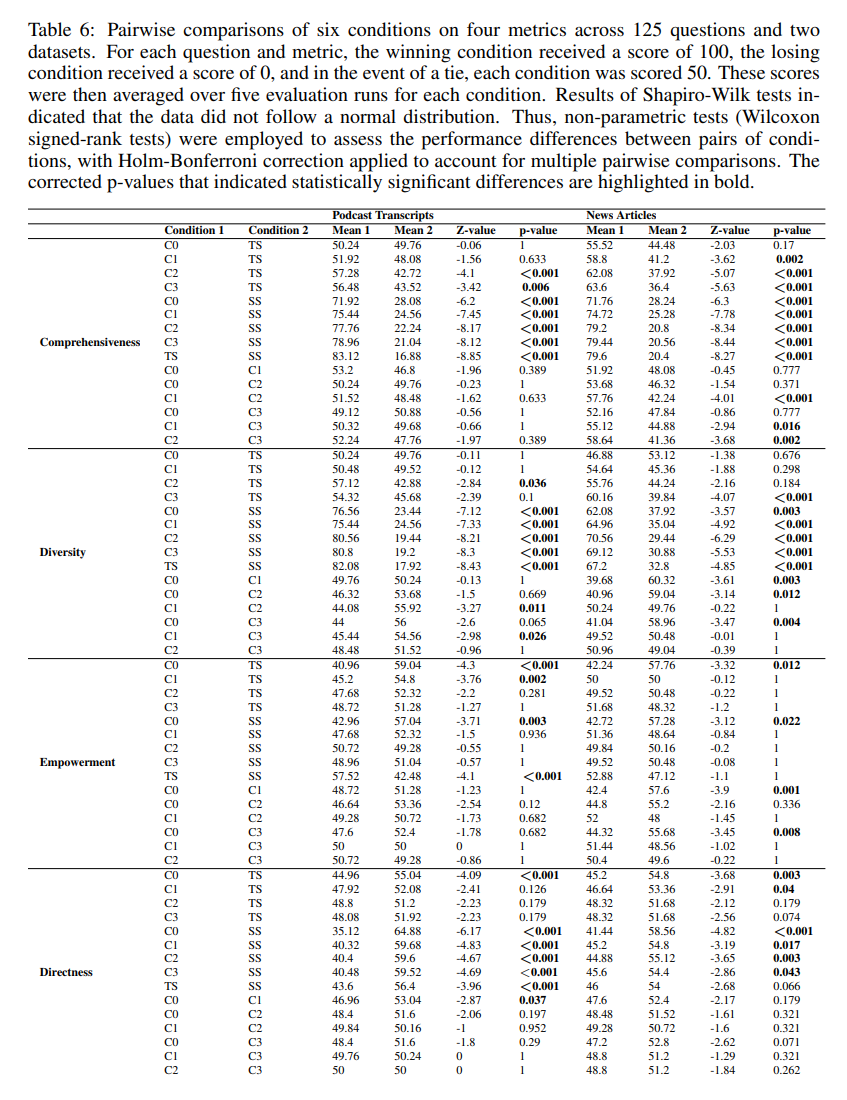 => Global approaches가 vector RAG 보다 훨씬 퍼포먼스가 좋은 것을 확인할 수 있다.
=> Global approaches가 vector RAG 보다 훨씬 퍼포먼스가 좋은 것을 확인할 수 있다. -
Community summaries vs. source texts
 => GraphRAG의 scalability advantages를 보여줌(대규모 데이터셋을 처리할 때 효율적인 성능)
=> GraphRAG의 scalability advantages를 보여줌(대규모 데이터셋을 처리할 때 효율적인 성능)같은 수준의 정보를 생성하는 데 더 적은 리소스와 토큰을 사용하여 대규모 데이터셋을 효율적으로 처리할 수 있다는 점.
즉, GraphRAG는 데이터가 커질수록 성능이 뛰어나고, 자원 소모가 적어지는 확장성이 뛰어난 시스템이라고 볼 수 있다.
Experiment 2
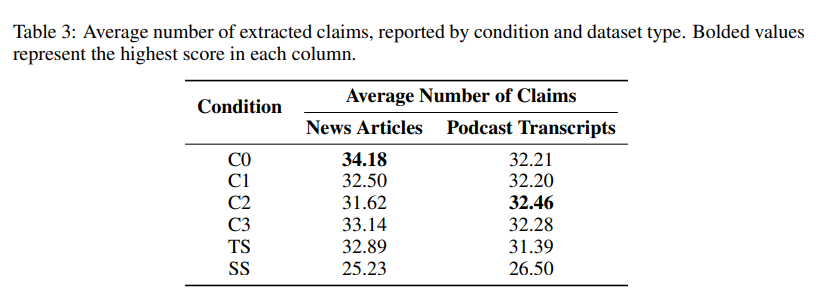
Experiment 1의 Comprehensiveness와 Diversity 결과를 사실 기반(claim-based) 지표로 검증하기 위함이다.
- Factual Claim 추출
- 정의: “검증 가능한 사실을 명시적으로 제시하는 문장”
-
예: “California and New York implemented incentives for renewable energy adoption.”
→ 두 개의 claim 포함:
(1) California 정책 시행, (2) New York 정책 시행.
- 도구: Claimify (Metropolitansky & Larson, 2025)
- 데이터 처리 과정
- Experiment 1의 각 조건(C0~C3, TS, SS)으로 생성된 답변에 Claimify 적용.
- 중복 claim 제거 후, 총 47,075개의 unique claim, 평균 31개/답변 추출.
- 평가 지표
- Comprehensiveness → 각 조건별 평균 claim 수로 측정됨
- Diversity → 각 답변에 대한 claim들을 군집화하여 평균 cluster 수를 계산하여 측정됨
- 알고리즘: Agglomerative Clustering (Scikit-learn)
- linkage: complete
- 거리 metric: 1 − ROUGE-L
- 여러 거리 임계값(0.5~0.8)을 실험
Results 2
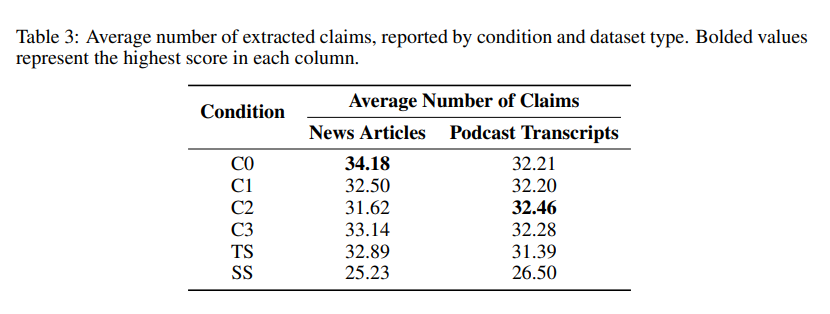
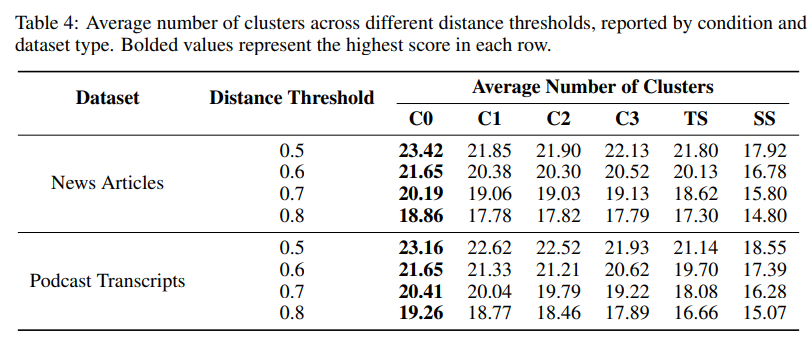
=> 전반적으로 GraphRAG가 성능이 좋은 걸 확인할 수 있다.
Limitations of Evaluation Approach
- 지금까지의 평가는 약 100만 토큰이 포함된 두 개의 특정 코퍼스에 대해 의미 추론(sensemaking) 질문을 중심으로 진행되었다. 그러나, 성능이 다른 도메인과 사용 사례에 어떻게 일반화되는지에 대한 추가적인 연구가 필요하다.
- SelfCheckGPT(Manakul et al., 2023)와 같은 방법을 사용하여 허위 생성(fabrication) 비율을 비교하면, 현재 분석을 더욱 강화할 수 있을 것이다.
Future Work
- 현재 GraphRAG의 그래프 인덱스, 풍부한 텍스트 주석, 계층적 커뮤니티 구조는 많은 개선&적용 가능성을 제공한다.
- 임베딩 기반 매칭을 사용한 로컬 RAG 방식이 가능하며, 이는 사용자 쿼리와 그래프 annotations를 더 효율적으로 처리할 수 있게 한다.
- 하이브리드 RAG 방식이 유망한 접근법으로, 임베딩 기반 매칭 + just-in-time 커뮤니티 보고서 생성을 결합하여, 맵-리듀스 요약을 사용하기 전에 빠르고 적절한 커뮤니티 요약을 생성할 수 있다.
- 임베딩 기반 매칭과 적시 커뮤니티 보고서 생성을 결합한 하이브리드 RAG 방식에서 잠재력
- “롤업” 접근법: 여러 커뮤니티 레벨을 확장하여 글로벌 요약을 생성하는 방법.
- “드릴 다운” 접근법: 상위 레벨 커뮤니티 요약을 기반으로, 더 상세한 하위 정보를 탐색하는 방식.
- AI 시스템의 신뢰성 향상
- GraphRAG는 글로벌 의미 추론에 있어 벡터 RAG보다 더 정확한 답변을 제공하므로, 잘못된 정보를 글로벌 요약으로 잘못 제시하는 문제를 줄일 수 있다.
Conclusion
- GraphRAG?
- GraphRAG는 지식 그래프 생성과 쿼리 중심 요약(QFS)을 결합한 RAG 접근법으로, 전체 텍스트 코퍼스에 대한 인간의 의미 추론(sensemaking)을 지원한다.
- 글로벌 쿼리 처리
- GraphRAG는 같은 데이터셋에 대해 많은 글로벌 쿼리를 처리할 때, 루트 레벨 커뮤니티 요약을 사용한 엔티티 기반 그래프 인덱스를 제공하며, 벡터 RAG보다 우수한 데이터 인덱스를 제공한다.
- 또한, 다른 글로벌 방법들과 경쟁할 수 있는 성능을 적은 토큰 비용으로 달성할 수 있다.
Opinion
논문을 읽다보니까 Global 질문에 대한 질문을 할거면, 그냥 일반 LLM 한테 문서 전체를 넘겨주고 물어보면 되지 않나? 그래프를 꼭 구축해야할까 라는 생각이 들었는데,
애초에 문서양이 너무 커지는 경우에 적합한 방법론인 것 같다.
그리고 사실 읽기 전에는 graphRAG라는게 지식 관계를 활용해서 답변의 투명성을 확보하고, 할루시네이션 현상을 더 줄이는 데 기여하는 방법론인 줄 알았는데 그것보다는 global적인 질문에 대한 답변을 잘 생성하는 게 초점인 기술이었네?
GraphRAG라는게 사실 Microsoft에서 낸 독자적인 기술 이름이라기 보다는 ..
좀 범용적인 단어를 조합해서 좀 헷갈리는게 아닌가 싶기도 ?
근데 이 논문에서 직접적으로 이런 지식 관계 활용의 장점을 언급하지는 않지만, 지식 그래프를 구축하고 진행하는 방법이기 때문에 답변 생성 과정을 추적하거나, 더 복잡한 추론을 가능하게 확장할 수 있다는 점을 장점으로 확장할 수 있을 것 같다.